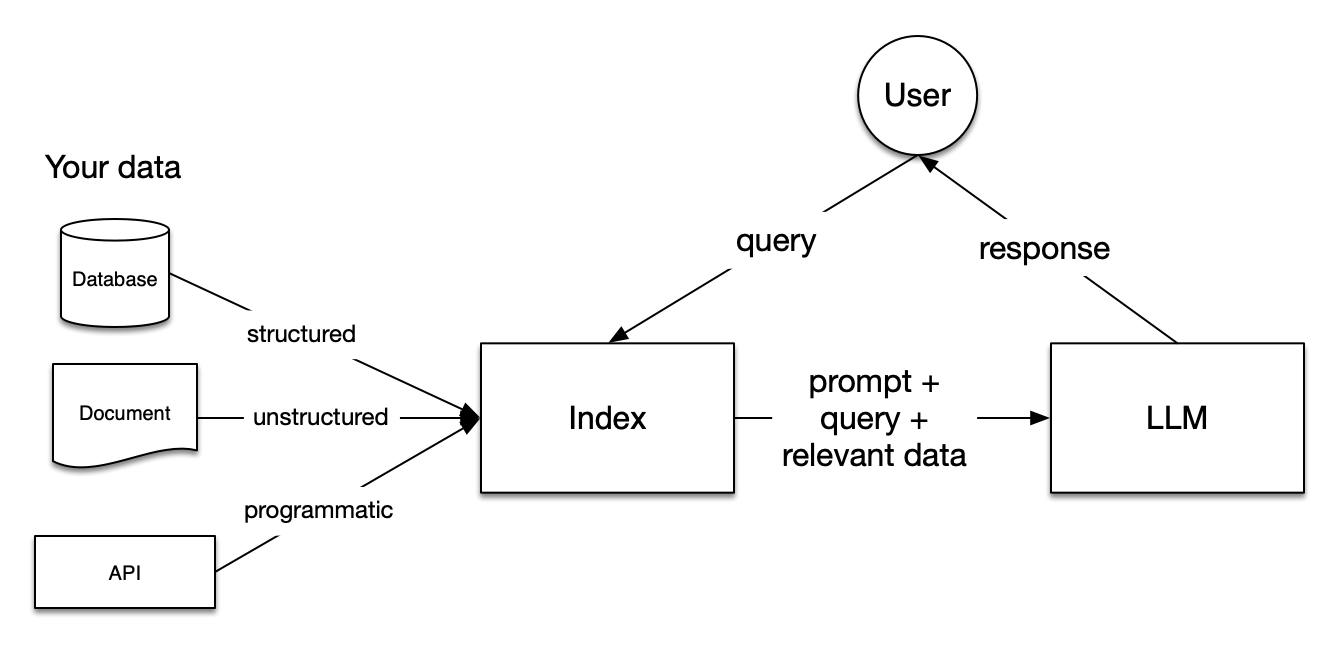
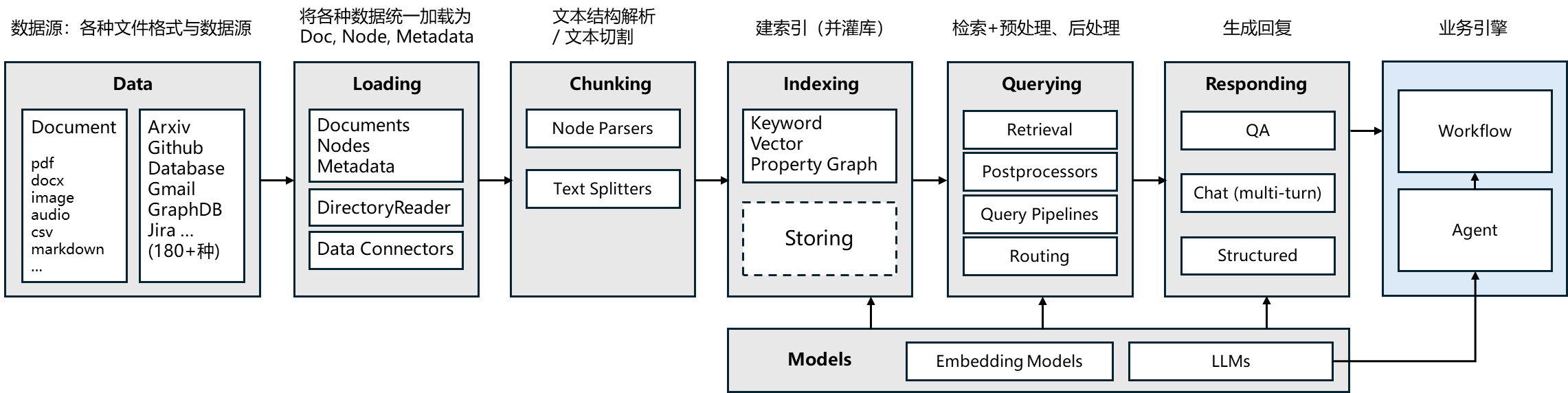
LlamaIndex 开发 RAG 的大模型应用框架。
LlamaIndex 核心模块
文档 https://docs.llamaindex.ai/en/stable/
API 接口文档 https://docs.llamaindex.ai/en/stable/api_reference/
数据加载与解析(Loading) SimpleDirectoryReader 本地文件加载器。遍历指定目录,并根据文件扩展名自动加载文件(文本内容 )。
支持的文件类型:.csv、.docx、.epub、.hwp、.ipynb、.jpeg, .jpg、.mbox、.md、.mp3, .mp4、.pdf、.png、.ppt, .pptm, .pptx
加载本地文件 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 from llama_index.core import SimpleDirectoryReaderreader = SimpleDirectoryReader( input_dir=r'./data' , recursive=False , required_exts=['.pdf' ] ) documents = reader.load_data() print (documents[0 ].text)
默认的 PDFReader 效果不是很理想,可更换文件加载器。(LlamaParse, https://cloud.llamaindex.ai/ 需申请 API key,配置 LLAMA_CLOUD_API_KEY=XXX)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 from llama_cloud_services import LlamaParsefrom llama_index.core import SimpleDirectoryReaderparser = LlamaParse( result_type="markdown" ) file_extractor = {".pdf" : parser} documents = SimpleDirectoryReader( input_dir="./data" , required_exts=[".pdf" ], file_extractor=file_extractor ).load_data() print (documents[0 ].text)
Data Connectors 用于处理更丰富的数据类型,并将其读取为 Document 的形式
1 2 3 4 5 6 7 8 9 10 11 12 from llama_index.readers.web import SimpleWebPageReaderdocuments = SimpleWebPageReader(html_to_text=True ).load_data( ["https://www.baidu.com" ] ) print (documents[0 ].text)
使用 NodeParsers 对有结构的文档做解析
HTMLNodeParser 解析 HTML 文档,还有 MarkdownNodeParser、JSONNodeParser 等
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 from llama_index.core.node_parser import HTMLNodeParserfrom llama_index.readers.web import SimpleWebPageReaderdocuments = SimpleWebPageReader(html_to_text=False ).load_data( ["https://liaoxuefeng.com/books/python/advanced/iterator/index.html" ] ) parser = HTMLNodeParser(tags=["span" ]) nodes = parser.get_nodes_from_documents(documents) for node in nodes: print (node.text+"\n" )
更多 Data Connectors
内置文件加载器 https://llamahub.ai/l/readers/llama-index-readers-file
连接三方服务的数据加载器,如数据库 https://docs.llamaindex.ai/en/stable/module_guides/loading/connector/modules/
更多加载器 https://llamahub.ai/
文本切分 为方便检索,通常将 Document 切分为 Node(chunk)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 from llama_index.core.node_parser import TokenTextSplitternode_parser = TokenTextSplitter( chunk_size=512 , chunk_overlap=200 ) nodes = node_parser.get_nodes_from_documents( documents, show_progress=False ) print (nodes[0 ].text)
更多的切割方式:
SentenceSplitter:切割指定长度 chunk 同时尽量保证句子边界不被切断;
CodeSplitter:根据 AST (编译器的抽象句法树)切分代码,保证代码功能片段完整;
SemanticSplitterNodeParser:根据语义相关性对将文本切割;
索引与检索 传统索引 、向量索引
向量检索
VectorStoreIndex 直接在内存中构建向量存储及索引
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 from llama_index.core import VectorStoreIndex, SimpleDirectoryReaderfrom llama_index.core.node_parser import TokenTextSplitter, SentenceSplitterfrom llama_index.embeddings.openai import OpenAIEmbeddingdocuments = SimpleDirectoryReader( "./data" , required_exts=[".pdf" ], ).load_data() node_parser = TokenTextSplitter(chunk_size=512 , chunk_overlap=200 ) nodes = node_parser.get_nodes_from_documents(documents) embed_model = OpenAIEmbedding() index = VectorStoreIndex(nodes,embed_model=embed_model) vector_retriever = index.as_retriever( similarity_top_k=2 ) results = vector_retriever.retrieve("deepseek v3数学能力怎么样?" ) print (results[0 ].text)
使用指定的向量数据库存储,eg:qdrant
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 from llama_index.core.indices.vector_store.base import VectorStoreIndexfrom llama_index.vector_stores.qdrant import QdrantVectorStorefrom llama_index.core import StorageContextfrom qdrant_client import QdrantClientfrom qdrant_client.models import VectorParams, Distanceclient = QdrantClient(location=":memory:" ) collection_name = "demo" collection = client.create_collection( collection_name=collection_name, vectors_config=VectorParams(size=1536 , distance=Distance.COSINE) ) vector_store = QdrantVectorStore(client=client, collection_name=collection_name) storage_context = StorageContext.from_defaults(vector_store=vector_store) index = VectorStoreIndex(nodes, storage_context=storage_context) vector_retriever = index.as_retriever(similarity_top_k=1 ) results = vector_retriever.retrieve("deepseek v3数学能力怎么样" ) print (results[0 ])
更多索引与检索方式
关键字检索
BM25Retriever:基于 tokenizer 实现的 BM25 经典检索算法KeywordTableGPTRetriever:使用 GPT 提取检索关键字KeywordTableSimpleRetriever:使用正则表达式提取检索关键字KeywordTableRAKERetriever:使用RAKE算法提取检索关键字(有语言限制)
RAG-Fusion QueryFusionRetriever
还支持 KnowledgeGraph、SQL、Text-to-SQL 等等
检索后处理
LlamaIndex 的 Node Postprocessors 提供了一系列检索后处理模块。eg:重排序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 from llama_index.core.postprocessor import LLMRerankpostprocessor = LLMRerank(top_n=2 ) nodes = postprocessor.postprocess_nodes(nodes, query_str="deepseek v3有多少参数?" ) for i, node in enumerate (nodes): print (f"[{i} ] {node.text} " )
生成回复 1 2 3 4 5 6 7 qa_engine = index.as_query_engine() response = qa_engine.query("deepseek v3数学能力怎么样?" ) print (response)response.print_response_stream()
1 2 3 4 5 6 7 8 9 10 chat_engine = index.as_chat_engine() response = chat_engine.chat("deepseek v3数学能力怎么样?" ) response = chat_engine.chat("代码能力呢?" ) print (response)streaming_response = chat_engine.stream_chat("deepseek v3数学能力怎么样?" ) for token in streaming_response.response_gen: print (token, end="" , flush=True )
底层接口 Prompt 模版 1 2 3 4 from llama_index.core import PromptTemplateprompt = PromptTemplate("写一个关于{topic}的笑话" ) prompt.format (topic="小明" )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 from llama_index.core.llms import ChatMessage, MessageRolefrom llama_index.core import ChatPromptTemplatechat_text_qa_msgs = [ ChatMessage( role=MessageRole.SYSTEM, content="你叫{name},你必须根据用户提供的上下文回答问题。" , ), ChatMessage( role=MessageRole.USER, content=( "已知上下文:\n" \ "{context}\n\n" \ "问题:{question}" ) ), ] text_qa_template = ChatPromptTemplate(chat_text_qa_msgs) print ( text_qa_template.format ( name="小明" , context="这是一个测试" , question="这是什么" ) )
调用 LLM 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 from llama_index.llms.openai import OpenAIllm = OpenAI(temperature=0 , model="gpt-4o" ) response = llm.complete(prompt.format (topic="小明" )) print (response.text)from llama_index.core import SettingsSettings.llm = DeepSeek(model="deepseek-chat" , api_key=os.getenv("DEEPSEEK_API_KEY" ), temperature=1.5 ) from llama_index.embeddings.openai import OpenAIEmbeddingfrom llama_index.core import SettingsSettings.embed_model = OpenAIEmbedding(model="text-embedding-3-small" , dimensions=512 )
支持多种语言模型 https://docs.llamaindex.ai/en/stable/module_guides/models/llms/modules/
基于 LlamaIndex 实现 RAG 基本功能:
加载指定目录的文件
RAG-Fusion
使用 Qdrant 向量数据库,并持久化到本地
检索后排序
多轮对话
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 import osfrom qdrant_client import QdrantClientfrom qdrant_client.models import VectorParams, DistanceEMBEDDING_DIM = 1536 COLLECTION_NAME = "full_demo" PATH = "./qdrant_db" client = QdrantClient(path=PATH) from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, get_response_synthesizerfrom llama_index.vector_stores.qdrant import QdrantVectorStorefrom llama_index.core.node_parser import SentenceSplitterfrom llama_index.core.response_synthesizers import ResponseModefrom llama_index.core.ingestion import IngestionPipeline from llama_index.core import Settingsfrom llama_index.core import StorageContextfrom llama_index.core.postprocessor import LLMRerank, SimilarityPostprocessorfrom llama_index.core.retrievers import QueryFusionRetrieverfrom llama_index.core.query_engine import RetrieverQueryEnginefrom llama_index.core.chat_engine import CondenseQuestionChatEnginefrom llama_index.llms.dashscope import DashScope, DashScopeGenerationModelsfrom llama_index.embeddings.dashscope import DashScopeEmbedding, DashScopeTextEmbeddingModelsSettings.llm = DashScope(model_name=DashScopeGenerationModels.QWEN_MAX, api_key=os.getenv("DASHSCOPE_API_KEY" )) Settings.embed_model = DashScopeEmbedding(model_name=DashScopeTextEmbeddingModels.TEXT_EMBEDDING_V1) Settings.transformations = [SentenceSplitter(chunk_size=512 , chunk_overlap=200 )] documents = SimpleDirectoryReader("./data" ).load_data() if client.collection_exists(collection_name=COLLECTION_NAME): client.delete_collection(collection_name=COLLECTION_NAME) client.create_collection( collection_name=COLLECTION_NAME, vectors_config=VectorParams(size=EMBEDDING_DIM, distance=Distance.COSINE) ) vector_store = QdrantVectorStore(client=client, collection_name=COLLECTION_NAME) storage_context = StorageContext.from_defaults(vector_store=vector_store) index = VectorStoreIndex.from_documents( documents, storage_context=storage_context ) reranker = LLMRerank(top_n=2 ) sp = SimilarityPostprocessor(similarity_cutoff=0.6 ) fusion_retriever = QueryFusionRetriever( [index.as_retriever()], similarity_top_k=5 , num_queries=3 , use_async=False , ) query_engine = RetrieverQueryEngine.from_args( fusion_retriever, node_postprocessors=[reranker], response_synthesizer=get_response_synthesizer( response_mode=ResponseMode.REFINE ) ) chat_engine = CondenseQuestionChatEngine.from_defaults( query_engine=query_engine, ) while True : question = input ("User:" ) if question.strip() == "" : break response = chat_engine.chat(question) print (f"AI: {response} " )
Text2SQL 将自然语言转换为 SQL 查询语句
一个成熟的Text2SQL系统需要具备以下关键能力:
核心能力
说明
技术挑战
语义理解
理解用户真正的查询意图
处理歧义、上下文推断
数据库结构感知
了解表结构、字段关系
自动映射字段与实体
复杂查询构建
支持多表连接、聚合等
子查询、嵌套逻辑转换
上下文记忆
理解多轮对话中的指代
维护查询状态
错误处理
识别并修正错误输入
模糊匹配、容错机制
技术架构:基于 Workflow 工作流、LangChain 的数据库链和企业级解决方案(Vanna 、自然语言到SQL语言转义(基于大语言模型的NL2SQL) 、自然语言生成智能图表NL2Chart 、ChatBI )
工作流 LlamaIndex 工作流由事件(event)驱动,由 step 组成,每个 step 处理特定的事件,直到产生 StopEvent 结束。
LlamaIndex Workflows: https://docs.llamaindex.ai/en/stable/module_guides/workflow/
使用自然语言查询数据库中的内容 基本流程:
用户输入自然语言查询
系统先去检索跟查询相关的表
根据表的 Schema 让大模型生成 SQL
用生成的 SQL 查询数据库
根据查询结果,调用大模型生成自然语言回复
https://docs.llamaindex.ai/en/stable/optimizing/production_rag/