开发大语言模型提供应用程序支持的框架
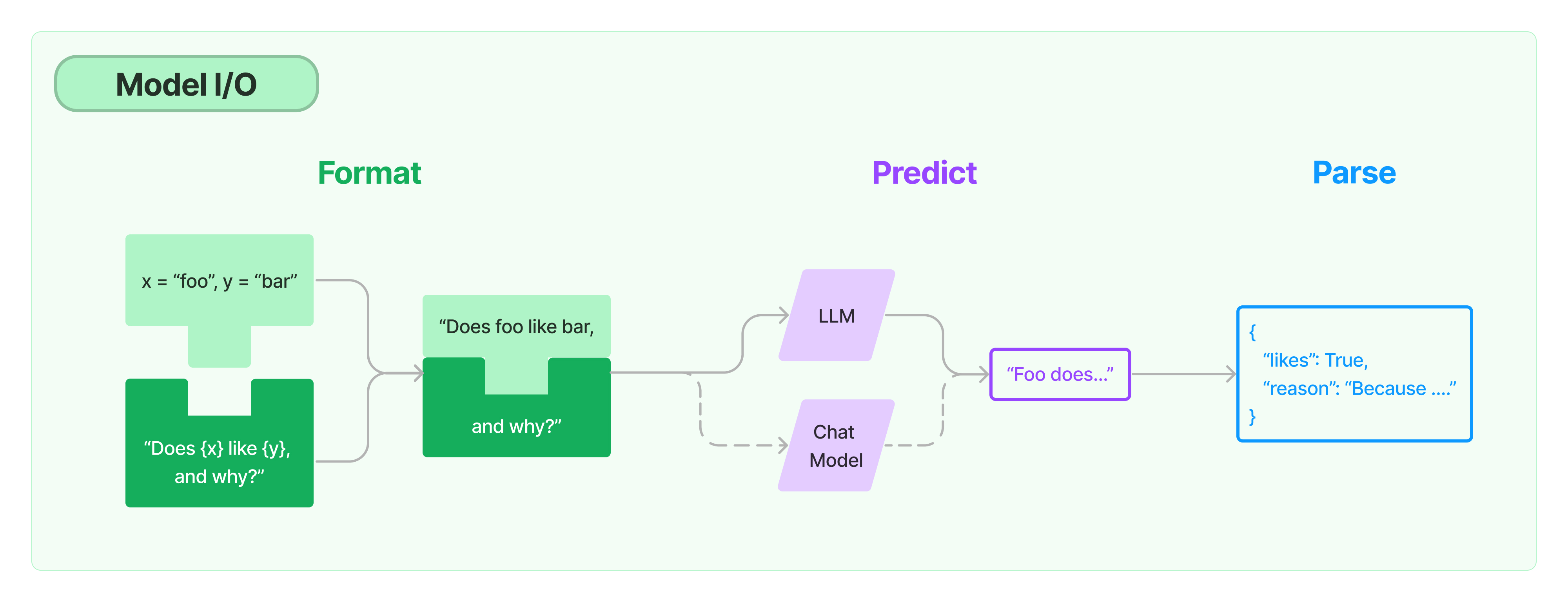
Langchain的核心组件:
模型(Models):包含各大语言模型的LangChain接口和调用细节,以及输出解析机制。
提示模板(Prompts):使提示工程流线化,进一步激发大语言模型的潜力。
数据检索(Indexes):构建并操作文档的方法,接受用户的查询并返回最相关的文档,轻松搭建本地知识库。
记忆(Memory):通过短时记忆和长时记忆,在对话过程中存储和检索数据,让ChatBot记住你。
链(Chains):LangChain中的核心机制,以特定方式封装各种功能,并通过一系列的组合,自动而灵活地完成任务。
代理(Agents):另一个LangChain中的核心机制,通过“代理”让大模型自主调用外部工具和内部工具,使智能Agent成为可能。
开源库组成:
langchain-core :基础抽象和LangChain表达式语言
langchain-community :第三方集成。合作伙伴包(如langchain-openai、langchain-anthropic等),一些集成已经进一步拆分为自己的轻量级包,只依赖于langchain-core
langchain :构成应用程序认知架构的链、代理和检索策略
langgraph:通过将步骤建模为图中的边和节点,使用 LLMs 构建健壮且有状态的多参与者应用程序
langserve:将 LangChain 链部署为 REST API
LangSmith:一个开发者平台,可让您调试、测试、评估和监控LLM应用程序,并与LangChain无缝集成
通过 API 的方式调用大模型 需要设置模型对应的 API_key,可以通过以下代码实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 import json import os.path def load_key (keyname: str ) -> str : file_name = "./Keys.json" if os.path.exists(file_name): with open (file_name, "r" ) as file: Key = json.load(file) if keyname in Key and Key[keyname]: return Key[keyname] else : keyval = input ("配置文件中没有对应的配置,请输入对应的配置信息:" ).strip() Key[keyname] = keyval with open (file_name, "w" ) as file: json.dump(Key, file, indent=4 ) return keyval else : keyval = input ("配置文件中没有对应的配置信息,请输入对应的配置信息:" ).strip() Key = { keyname: keyval } with open (file_name, "w" ) as file: json.dump(Key, file, indent=4 ) return keyval if __name__ == "__main__" : print (load_key("LANGSMITH_API_KEY" ))
1 2 3 4 5 import os from config.load_key import load_key if not os.environ.get("OPENAI_API_KEY" ): os.environ["OPENAI_API_KEY" ] = load_key("OPENAI_API_KEY" )
可通过如下代码对 API_key 的使用进行监控(需注册申请并配置 LangSmith API_key https://smith.langchain.com/ )
1 2 3 4 5 6 import os from config.load_key import load_key os.environ["LANGSMITH_TRACING" ] = "true" os.environ["LANGSMITH_PROJECT" ] = "LangChain_Learning_test" os.environ["LANGSMITH_API_KEY" ] = load_key("LANGSMITH_API_KEY" )
也可以直接在调用模型时直接给定 API_key ,不过上面这种更方便且安全
模型的调用和基本使用 1 2 3 4 5 6 7 8 9 from langchain.chat_models import init_chat_model model = init_chat_model( "gpt-3.5-turbo" , model_provider="openai" , )
在模型调用时支持传入更多定制的参数,eg:temperature、top_p 等,从而得到不同的模型输出效果
1 2 3 4 5 6 7 8 9 from langchain_core.messages import HumanMessage, SystemMessage messages = [ SystemMessage("Translate the following from English into Chinese" ), HumanMessage("I love programming." ), ] model.invoke(messages)
在与大模型交互时,有多种不同的消息作为不同的角色输入给大模型作为提示词
user/HumanMessage :用户输入的问题
system/SystemMessage :系统角色,描述问题的背景及当前大模型充当的角色
assistant/AIMessage :模型输出的答案
1 2 3 4 5 model.invoke("Hello" ) model.invoke([{"role" : "user" , "content" : "Hello" }]) model.invoke([HumanMessage("Hello" )])
LangChain 也对 OpenAI 的调用方式做了封装(以不同的方式调用不同的模型,需要安装对应的依赖)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 from langchain_openai import ChatOpenAI llm = ChatOpenAI( model="gpt-3.5-turbo" , ) llm.invoke([ SystemMessage("Translate the following from English into Chinese" ), HumanMessage("I love programming." ) ]) from langchain_deepseek import ChatDeepSeek llm = ChatDeepSeek( model="deepseek-chat" ) llm.invoke([HumanMessage("你是谁?你可以干什么?" )]) from langchain_openai import ChatOpenAI from langchain_core.messages.human import HumanMessage llm = ChatOpenAI( model="deepseek-v3" , base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" , openai_api_key=load_key("BAILIAN_API_KEY" ), ) llm.invoke([HumanMessage("你是谁?你可以干什么?" )])
流式输出
1 2 3 stream = llm.stream([HumanMessage("你是谁?你可以干什么?" )]) for chunk in stream: print (chunk.content, end="" )
模型输入与输出
提示词模版
将 Prompt 模版看作带有参数的函数
基本使用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 from langchain.prompts import PromptTemplate template = PromptTemplate.from_template("给我讲个关于{subject}的笑话" ) print (template) print (template.format (subject='小明' )) result = llm.invoke(template.format (subject='小明' )) print (result.content)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 from langchain_core.prompts import ChatPromptTemplateprompt_template = ChatPromptTemplate.from_messages([ ("system" , "Translate the following from English into {language}" ), ("user" ,"{text}" ) ]) ''' prompt_template = ChatPromptTemplate.from_messages( [ SystemMessagePromptTemplate.from_template("Translate the following from English into {language}"), HumanMessagePromptTemplate.from_template("{text}") ] ) ''' prompt = prompt_template.format_messages(language="Chinese" , text="I love programming." ) response = llm.invoke(prompt) print (response.content)
把多轮对话变成模版 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 from langchain.prompts import ( ChatPromptTemplate, HumanMessagePromptTemplate, MessagesPlaceholder, ) human_prompt = "Translate your answer to {language}." human_message_template = HumanMessagePromptTemplate.from_template(human_prompt) chat_prompt = ChatPromptTemplate.from_messages( [MessagesPlaceholder("history" ), human_message_template] ) from langchain_core.messages import AIMessage, HumanMessagehuman_message = HumanMessage(content="Who is Elon Musk?" ) ai_message = AIMessage( content="Elon Musk is a billionaire entrepreneur, inventor, and industrial designer" ) messages = chat_prompt.format_prompt( history=[human_message, ai_message], language="中文" ) print (messages.to_messages())result = llm.invoke(messages) print (result.content)
结构化输出 直接输出 Pydantic 对象 1 2 3 4 5 6 7 8 from pydantic import BaseModel, Fieldclass Date (BaseModel ): year: int = Field(description="Year" ) month: int = Field(description="Month" ) day: int = Field(description="Day" ) era: str = Field(description="BC or AD" )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 from langchain.prompts import PromptTemplatestructured_llm = llm.with_structured_output(Date) template = """提取用户输入中的日期。 用户输入: {query}""" prompt = PromptTemplate( template=template, ) query = "2023年四月6日天气晴..." input_prompt = prompt.format_prompt(query=query) structured_llm.invoke(input_prompt)
输出指定的格式 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 json_schema = { "title" : "Date" , "description" : "Formated date expression" , "type" : "object" , "properties" : { "year" : { "type" : "integer" , "description" : "year, YYYY" , }, "month" : { "type" : "integer" , "description" : "month, MM" , }, "day" : { "type" : "integer" , "description" : "day, DD" , }, "era" : { "type" : "string" , "description" : "BC or AD" , }, }, } structured_llm = llm.with_structured_output(json_schema) structured_llm.invoke(input_prompt)
不同的方式结构化输出
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 from langchain_core.output_parsers import JsonOutputParserparser = JsonOutputParser(pydantic_object=Date) prompt = PromptTemplate( template="提取用户输入中的日期。\n用户输入:{query}\n{format_instructions}" , input_variables=["query" ], partial_variables={"format_instructions" : parser.get_format_instructions()}, ) input_prompt = prompt.format_prompt(query=query) output = llm.invoke(input_prompt) print ("原始输出:\n" +output.content)print ("\n解析后:" )parser.invoke(output)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 from langchain_core.output_parsers import PydanticOutputParserparser = PydanticOutputParser(pydantic_object=Date) input_prompt = prompt.format_prompt(query=query) output = llm.invoke(input_prompt) print ("原始输出:\n" + output.content)print ("\n解析后:" )parser.invoke(output)
利用大模型做格式自动纠错
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 from langchain.output_parsers import OutputFixingParsernew_parser = OutputFixingParser.from_llm(parser=parser, llm=llm) bad_output = output.content.replace("4" , "四" ) try : parser.invoke(bad_output) except Exception as e: print (e) new_parser.invoke(bad_output)
LCEL 表达式 LangChain Expression Language(LCEL),方便组合不同的调用顺序构成 Chain,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 from langchain_core.output_parsers import StrOutputParser from langchain_core.prompts import ChatPromptTemplate from langchain_openai import ChatOpenAI from config.load_key import load_key prompt_template = ChatPromptTemplate.from_messages([ ("system" , "Translate the following from English into {language}" ), ("user" , "{text}" ) ]) llm = ChatOpenAI( model="deepseek-v3" , base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" , openai_api_key=load_key("BAILIAN_API_KEY" ), ) parser = StrOutputParser() chain = prompt_template | llm | parser print (chain.invoke({"language" : "Chinese" , "text" : "I love programming." })) analysis_prompt = ChatPromptTemplate.from_template(("我应该怎么回答这句话?{talk}。给出10字以内总结性的回答" )) chain2 = {"talk" : chain} | analysis_prompt | llm | parser print (chain2.invoke({"language" : "Chinese" , "text" : "I love programming." }))
示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 from langchain.prompts import ChatPromptTemplate from langchain_core.output_parsers import StrOutputParser from langchain_core.runnables import RunnablePassthrough from pydantic import BaseModel, Field from typing import List , Dict , Optional from enum import Enum import json from langchain.chat_models import init_chat_model class SortEnum (str , Enum): data = 'data' price = 'price' class OrderingEnum (str , Enum): ascend = 'ascend' descend = 'descend' class Semantics (BaseModel ): name: Optional [str ] = Field(description="流量包名称" , default=None ) price_lower: Optional [int ] = Field(description="价格下限" , default=None ) price_upper: Optional [int ] = Field(description="价格上限" , default=None ) data_lower: Optional [int ] = Field(description="流量下限" , default=None ) data_upper: Optional [int ] = Field(description="流量上限" , default=None ) sort_by: Optional [SortEnum] = Field(description="按价格或流量排序" , default=None ) ordering: Optional [OrderingEnum] = Field(description="升序或降序排列" , default=None ) prompt = ChatPromptTemplate.from_messages( [ ("system" , "你是一个语义解析器。你的任务是将用户的输入解析成JSON表示。不要回答用户的问题。" ), ("human" , "{text}" ), ] ) llm = init_chat_model("deepseek-chat" , model_provider="deepseek" ) structured_llm = llm.with_structured_output(Semantics) ''' # 这里会导致一个大模型输出格式的问题 runnable = ( {"text": RunnablePassthrough()} | prompt | structured_llm ) ''' from langchain_core.runnables import RunnableLambdadef clear_formate (text: str ): if text.startswith('```json' ): text = text[7 :] if text.endswith('```' ): text = text[:-3 ] return text runnable = ( {"text" : RunnablePassthrough()} | prompt | llm | StrOutputParser() | RunnableLambda(clear_formate) | RunnableLambda(lambda x: Semantics.model_validate_json(x)) ) ''' # 将输入直接传递给提示模板 # runnable = {"text": RunnablePassthrough()} | prompt # 等价于: # runnable = {"text": lambda x: x} | prompt ''' ''' # 示例:复杂组合 runnable = ( {"text": RunnablePassthrough(), "extra": lambda x: "附加信息"} | prompt | llm ) # 这会将输入作为 text 传递,同时添加一个固定的 extra 字段 ''' ret = runnable.invoke("不超过100元的流量大的套餐有哪些" ) print ( json.dumps( ret.model_dump(), indent=4 , ensure_ascii=False ) )
设置调用不同的模型
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 from langchain_core.runnables.utils import ConfigurableField from langchain_community.chat_models import QianfanChatEndpoint from langchain.prompts import ( ChatPromptTemplate, HumanMessagePromptTemplate, ) from langchain.chat_models import init_chat_model from langchain.schema import HumanMessage import os ds_model = init_chat_model("deepseek-chat" , model_provider="deepseek" ) gpt_model = init_chat_model("gpt-4o-mini" , model_provider="openai" ) qwen_model = init_chat_model("qwen-plus" , model_provider="aliyun" ) model = gpt_model.configurable_alternatives( ConfigurableField(id ="llm" ), default_key="gpt" , deepseek=ds_model, qwen=qwen_model, ) prompt = ChatPromptTemplate.from_messages( [ HumanMessagePromptTemplate.from_template("{query}" ), ] ) chain = ( {"query" : RunnablePassthrough()} | prompt | model | StrOutputParser() ) ret = chain.with_config(configurable={"llm" : "gpt" }).invoke("请自我介绍" ) ret = chain.with_config(configurable={"llm" : "deepseek" }).invoke("请自我介绍" ) print (ret)
可以构建多个并行的问答链,构建复杂的大模型应用逻辑
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 from langchain_core.prompts import ChatPromptTemplatefrom langchain_core.runnables import RunnableMap, RunnableLambda, RunnableWithMessageHistory prompt_template_zh = ChatPromptTemplate.from_messages([ ("system" , "Translate the following from English into Chinese" ), ("user" , "{text}" ) ]) prompt_template_fr = ChatPromptTemplate.from_messages([ ("system" , "Translate the following from English into French" ), ("user" , "{text}" ) ]) chain_zh = prompt_template_zh | llm | parser chain_fr = prompt_template_fr | llm | parser parallel_chains = RunnableMap({ "zh_translation" : chain_zh, "fr_translation" : chain_fr, }) final_chain = parallel_chains | RunnableLambda(lambda x: f"Chinese:{x['zh_translation' ]} \nFrech: {x['fr_translation' ]} " ) print (final_chain.invoke("I love programming." ))
可根据不同的需求来动态构建不同的链。
LangChain 中只要是顶级父类 Runnable 的子类,都可以链接成一个序列。
更多操作:
更多例子: https://python.langchain.com/docs/how_to/lcel_cheatsheet/
多轮对话 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 from langchain_core.chat_history import InMemoryChatMessageHistory history = InMemoryChatMessageHistory() history.add_user_message("I love programming." ) aimessage = llm.invoke(history.messages) print (aimessage.content) history.add_ai_message(aimessage) history.add_user_message("重复回答" ) aimessage2 = llm.invoke(history.messages) print (aimessage2.content) history.add_ai_message(aimessage2) print ("Chat History:" ) for message in history.messages: print (f"{type (message).__name__} : {message.content} " )
存储到对应的存储系统中,而不是内存中(结束即丢失~)
LangChain 提供基于其他存储系统的扩展依赖: https://python.langchain.com/docs/integrations/memory/
以 Redis 为例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 from langchain_redis import RedisChatMessageHistory history = RedisChatMessageHistory( session_id="test" , url="redis://localhost:6379" , ) history.add_user_message("I love programming." ) aimessage = llm.invoke(history.messages) print (aimessage.content) history.add_ai_message(aimessage) history.add_user_message("重复回答" ) aimessage2 = llm.invoke(history.messages) print (aimessage2.content) history.add_ai_message(aimessage2)
聊天历史消息整合 LCEL
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 from langchain_core.runnables.history import RunnableWithMessageHistory llm = ChatOpenAI( model="deepseek-v3" , base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" , openai_api_key=load_key("BAILIAN_API_KEY" ), ) runnable = RunnableWithMessageHistory( llm, get_session_history=lambda : history, ) runnable.invoke("重复回答" ) prompt_template = ChatPromptTemplate.from_messages([ ("user" , "{text}" ) ]) chain = prompt_template | llm | parser runnable = RunnableWithMessageHistory( chain, get_session_history=lambda : history, ) runnable.invoke("text" : "重复回答" )
通过调用外部 API 接口,获取外部数据,然后让大模型再使用这些数据输出期望的内容。
https://python.langchain.com/docs/integrations/chat/
原生 OpenAI 函数调用 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 import jsonfrom openai import OpenAIclient = OpenAI() def get_current_weather (location, unit="celsius" ): """模拟获取天气信息的函数""" weather_info = { "location" : location, "temperature" : 22 if unit == "celsius" else 72 , "unit" : unit, "description" : "晴朗" } return json.dumps(weather_info) def get_stock_price (symbol ): """模拟获取股票价格的函数""" stock_data = { "symbol" : symbol, "price" : 150.25 , "change" : "+1.5%" } return json.dumps(stock_data) functions = [ { "name" : "get_current_weather" , "description" : "获取指定地点的当前天气信息" , "parameters" : { "type" : "object" , "properties" : { "location" : { "type" : "string" , "description" : "城市名,例如:北京、上海" }, "unit" : { "type" : "string" , "enum" : ["celsius" , "fahrenheit" ] } }, "required" : ["location" ] } }, { "name" : "get_stock_price" , "description" : "获取指定股票代码的当前价格" , "parameters" : { "type" : "object" , "properties" : { "symbol" : { "type" : "string" , "description" : "股票代码,例如:AAPL、GOOGL" } }, "required" : ["symbol" ] } } ] def run_conversation (): messages = [ {"role" : "user" , "content" : "今天北京的天气怎么样?" } ] response = client.chat.completions.create( model="gpt-3.5-turbo" , messages=messages, functions=functions, function_call="auto" ) message = response.choices[0 ].message if message.function_call: function_name = message.function_call.name function_args = json.loads(message.function_call.arguments) print (f"模型决定调用函数: {function_name} " ) print (f"函数参数: {function_args} " ) if function_name == "get_current_weather" : function_response = get_current_weather( location=function_args.get("location" ), unit=function_args.get("unit" , "celsius" ) ) elif function_name == "get_stock_price" : function_response = get_stock_price( symbol=function_args.get("symbol" ) ) print (f"函数返回结果: {function_response} " ) messages.append(message) messages.append({ "role" : "function" , "name" : function_name, "content" : function_response }) second_response = client.chat.completions.create( model="gpt-3.5-turbo" , messages=messages ) return second_response.choices[0 ].message.content else : return message.content if __name__ == "__main__" : result = run_conversation() print ("最终回答:" , result)
用JSON格式详细描述每个函数的名称、功能描述和参数规范
包括参数类型、是否必需等信息,让大模型能够理解如何调用
第一次调用:发送用户问题给模型,模型决定是否需要调用函数
函数调用判断:检查模型响应中是否包含 function_call
本地函数执行:根据模型返回的函数名和参数,在本地执行相应函数
结果回传:将函数执行结果作为新的消息发送给模型
第二次调用:模型基于函数结果生成最终的自然语言回答
手动模拟 Agent 工具调用
半自动工具调用,需要手动管理消息列表和调用流程
在与大模型聊天的过程中告诉模型本地应用能提供哪些工具来使用。
示例:大模型获取当前日期
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 import datetime from langchain.tools import tool from langchain_openai import ChatOpenAI from config.load_key import load_key llm = ChatOpenAI( model="deepseek-v3" , base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" , openai_api_key=load_key("BAILIAN_API_KEY" ), ) @tool def get_current_date (): """获取今天日期""" return datetime.datetime.today().strftime("%Y-%m-%d" ) llm_with_tools = llm.bind_tools([get_current_date]) query = "今天是几号" messages = [HumanMessage(query)] ai_msg = llm_with_tools.invoke(messages) print (ai_msg.tool_calls) messages.append(ai_msg) all_tools = {"get_current_date" : get_current_date} if ai_msg.tool_calls: for tool_call in ai_msg.tool_calls: selected_tool = all_tools[tool_call["name" ].lower()] tool_msg = selected_tool.invoke(tool_call) messages.append(tool_msg) print (llm_with_tools.invoke(messages).content)
模型第一次会返回一个带有 tool_calls 属性的 ai_msg ,即需要调用的工具。随后再执行对应的工具方法,将执行结果和之前的消息一起传递给大模型,模型综合工具给出答案。
自定义工具名称 1 2 3 4 5 @tool("get_current_date" def get_current_date (): """获取今天的日期""" return datetime.datetime.today().strftime("%Y-%m-%d" )
自定义工具描述 该描述是给大模型用的,模型会根据该描述来判断是否需要调用这个工具。描述信息可以直接添加注释,也可以用@tool装饰器的参数来定制。定义工具时,除了需要定义工具的描述,还可以定义参数的描述,模型也可以通过参数的描述来判断如何调用该工具。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 from langchain.tools import tool from langchain_openai import ChatOpenAI from config.load_key import load_key llm = ChatOpenAI( model="deepseek-v3" , base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" , openai_api_key=load_key("BAILIAN_API_KEY" ), ) @tool(description="获取某个城市的天气" ) def get_city_weather (city: str ): """获取某个城市的天气 Args: city: 具体城市 """ return "城市" + city + "今天天气不错" llm_with_tools = llm.bind_tools([get_city_weather]) all_tools = {"get_city_weather" : get_city_weather} query = "西安什么天气" messages = [query] ai_msg = llm_with_tools.invoke(messages) messages.append(ai_msg) print (ai_msg.tool_calls) if ai_msg.tool_calls: for tool_call in ai_msg.tool_calls: selected_tool = all_tools[tool_call["name" ].lower()] tool_msg = selected_tool.invoke(tool_call) messages.append(tool_msg) print (llm_with_tools.invoke(messages).content)
深度定制工具 StructuredTool.from_function 来结构化定制工具,其比 @tools 具有更多的属性配置。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 from langchain_openai import ChatOpenAI from langchain_core.tools import StructuredTool from config.load_key import load_key llm = ChatOpenAI( model="deepseek-v3" , base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" , openai_api_key=load_key("BAILIAN_API_KEY" ), ) def bad_city_weather (city: str ): """获取某个城市的天气 Args: city: 具体城市 """ return "城市" + city + "今天天气不错" weatherTool = StructuredTool.from_function( func=bad_city_weather, description="获取某个城市的天气" , name="bad_city_weather" ) all_tools = {"bad_city_weather" : weatherTool} llm_with_tools = llm.bind_tools([weatherTool]) query = "西安什么天气" messages = [query] ai_msg = llm_with_tools.invoke(messages) messages.append(ai_msg) print (ai_msg.tool_calls) if ai_msg.tool_calls: for tool_call in ai_msg.tool_calls: selected_tool = all_tools[tool_call["name" ].lower()] tool_msg = selected_tool.invoke(tool_call) messages.append(tool_msg) print (llm_with_tools.invoke(messages).content)
结合大模型定制工具 LangChain 允许将一个接收字符串或字典作为参数的 Runnable 实例直接转换成一个工具。
langchain 0.3 版本测试阶段
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 import datetime from langchain_openai import ChatOpenAI from langchain_core.output_parsers import StrOutputParser from langchain_core.prompts.chat import ChatPromptTemplate from config.load_key import load_key llm = ChatOpenAI( model="deepseek-v3" , base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" , openai_api_key=load_key("BAILIAN_API_KEY" ), ) prompt = ChatPromptTemplate.from_messages([ ("human" , "你好,请用下面这种语言回答我的问题:{language}。" ) ]) parser = StrOutputParser() chain = prompt | llm | parser as_tool = chain.as_tool( name="translatetool" , description="翻译工具" ) all_tools = {"translatetool" : as_tool} print (as_tool.args) llm_with_tools = llm.bind_tools([as_tool]) query = "好好学习,天天向上" messages = [query] ai_msg = llm_with_tools.invoke(messages) messages.append(ai_msg) print (ai_msg.tool_calls) if ai_msg.tool_calls: for tool_call in ai_msg.tool_calls: selected_tool = all_tools[tool_call["name" ].lower()] tool_msg = selected_tool.invoke(tool_call) messages.append(tool_msg) print (llm_with_tools.invoke(messages).content)
LangChain 提供的工具: https://python.langchain.com/docs/integrations/tools/
Agent 调用工具
全自动工具调用,Agent 自动决定何时调用工具及如何处理结果
简化上面自己判定并调用 tool_call ,保存历史信息的操作。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 from langchain.tools import tool from langchain.agents import initialize_agent, AgentType from langchain_openai import ChatOpenAI from config.load_key import load_key llm = ChatOpenAI( model="deepseek-v3" , base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" , openai_api_key=load_key("BAILIAN_API_KEY" ), ) @tool(description="获取某个城市的天气" ) def get_city_weather (city: str ): """获取某个城市的天气 Args: city: 具体城市 """ return "城市" + city + "今天天气不错" agent = initialize_agent( tools=[get_city_weather], llm=llm, agent=AgentType.OPENAI_FUNCTIONS, verbose=True , ) query = "西安什么天气" response = agent.invoke(query) print (response)
该智能体会在回答问题之前尝试进行推理。它会判断是否需要调用工具,若需要则调用,随后根据其返回结果,重新生成问题,直到得到一个答案为止。
示例 new 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 from langchain_openai import ChatOpenAI from langchain import hub from langchain_tavily import TavilySearch from langchain.agents import create_openai_functions_agent from langchain.agents import AgentExecutor from dotenv import load_dotenv load_dotenv() llm = ChatOpenAI( temperature=0.95 , model="qwen-plus" , openai_api_key='sk-31bb7a65dd4047aba9b14a95c08be52c' , openai_api_base="https://dashscope.aliyuncs.com/compatible-mode/v1" ) search = TavilySearch() tools = [search] prompt = hub.pull("hwchase17/openai-functions-agent" ) ''' custom_prompt = ChatPromptTemplate.from_messages([ ("system", """你是一个 helpful 的 AI 助手,能够使用可用的工具来帮助用户解决问题。 你可以使用以下工具: {tools} 请根据用户的输入决定是否需要使用工具,以及使用哪个工具。"""), ("user", "{input}"), MessagesPlaceholder(variable_name="agent_scratchpad") # 用于存储中间步骤 ]) ''' print (prompt) agent = create_openai_functions_agent(llm, tools, prompt) agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True , handle_parsing_errors=True ) agent_executor.invoke({"input" : "目前市场上苹果手机16的各个型号的售价是多少?" }) res = agent_executor.invoke({"input" : "你好?我丢雷老牟啊~" }) chat_history = [] chat_history.append(HumanMessage(content=res['input' ])) chat_history.append(AIMessage(content=res['output' ])) agent_executor.invoke( { "input" : "我丢什么啊?" , "chat_history" : chat_history } )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 from langchain_core.tools import Tooltools = [Tool( name="func01" , func=func01, description="工具函数描述01" , args={"参数01" : "参数描述01" } ), Tool( name="func02, func=func02, description=" 工具函数描述02", args={" 参数02": " 参数描述02"} ) ] # 工具调用和上面的方式一样 # agent = create_openai_functions_agent...(直接匹配函数调用) # agent = create_self_ask_with_search_agent...(主动提问获取信息) # agent = create_react_agent...(推理+行动循环) # 工具灵活使用,可以在工具函数中调用外部API工具,再用agent调用该工具函数~
使用向量数据库
LangChain 支持的向量数据库: https://python.langchain.com/docs/integrations/vectorstores/
示例:以 Redis 向量数据库为例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 from langchain_community.embeddings import DashScopeEmbeddings embedding_model = DashScopeEmbeddings( model="text-embedding-v1" , ) redis_url = "redis://localhost:6379" import redis redis_client = redis.from_url(redis_url) print (redis_client.ping()) from langchain_redis import RedisConfig, RedisVectorStore config = RedisConfig( index_name="fruit" , redis_url=redis_url, ) vector_store = RedisVectorStore(embedding_model, config=config) vector_store.add_texts(["香蕉好哇" , "苹果还行" , "西瓜又大又圆" ]) scored_results = vector_store.similarity_search_with_score("哪个水果最香" , k=2 ) for doc, score in scored_results: print (f"{doc.page_content} - {score} " ) retriver = vector_store.as_retriever(search_type="similarity" , search_kwargs={"k" : 2 }) retriver.invoke("哪个水果最香" )
链式使用 Retriver 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 from langchain_core.prompts import ChatPromptTemplate prompt = ChatPromptTemplate.from_messages([ ("human" , "请根据以下的上下文,回答问题:{question}" ), ]) def format_prompt_value (prompt_value ): return prompt_value.to_string() chain = prompt | format_prompt_value | retriver documents = chain.invoke({"question" : "哪个水果最香" }) for doc in documents: print (doc.page_content)
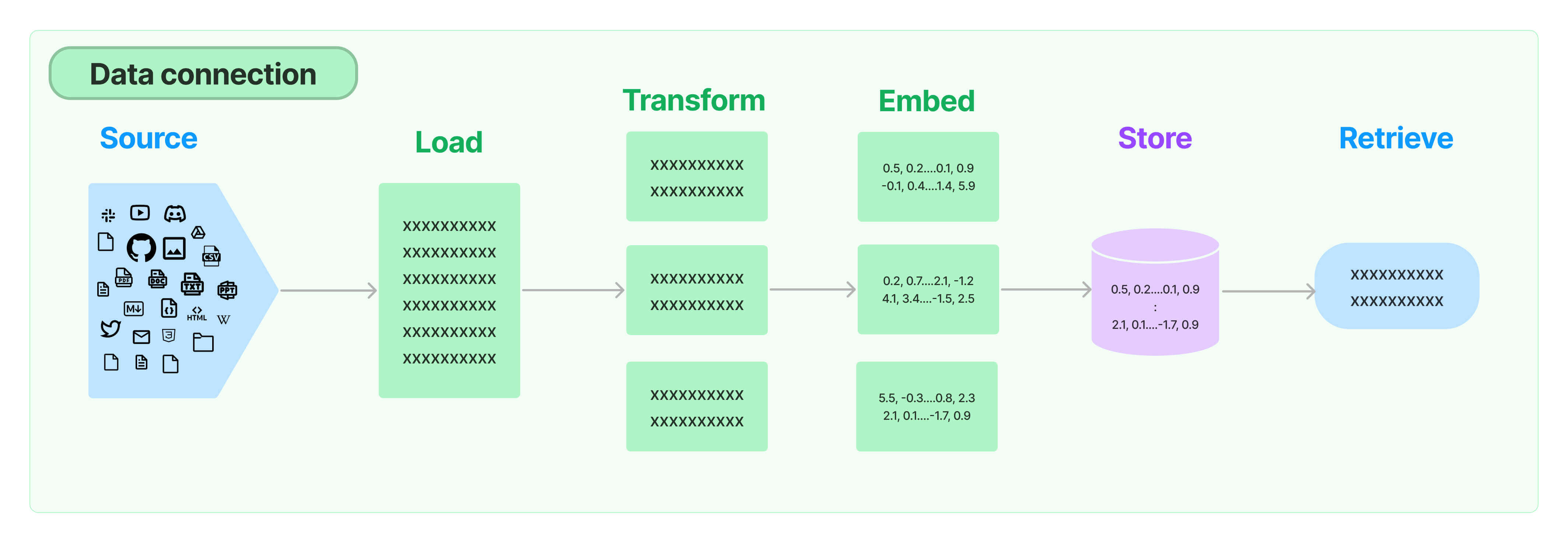
构建RAG问答流程 索引构建
主要对相关文档处理,形成知识库,便于后续检索
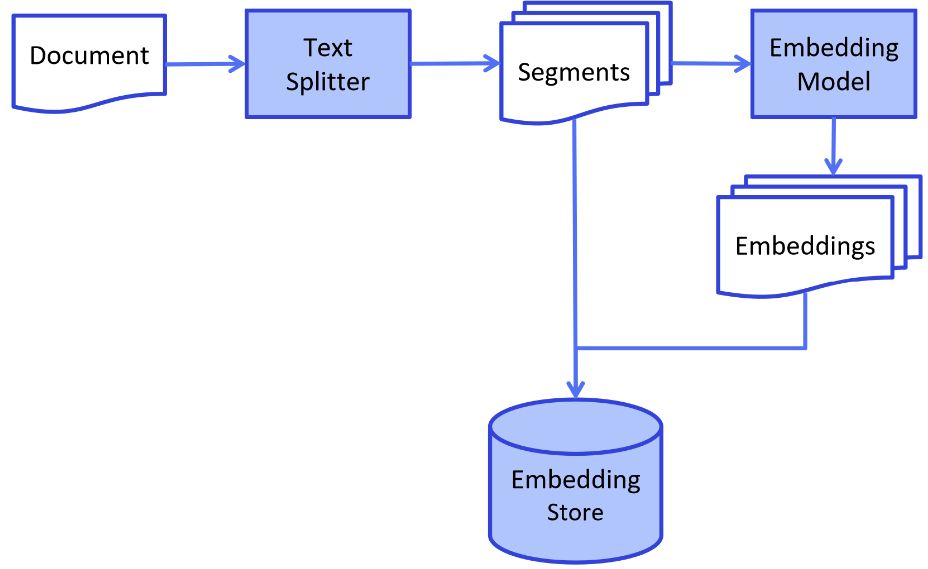
加载并解析文档
LangChain 中很多的 DocumentLoader 工具,可以加载各种文档格式的数据。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 from langchain_community.document_loaders import PyMuPDFLoader loader = PyMuPDFLoader("./data/deepseek-v3-1-4.pdf" ) pages = loader.load_and_split() print (pages[0 ].page_content)from langchain_text_splitters import RecursiveCharacterTextSplitter text_splitter = RecursiveCharacterTextSplitter( chunk_size=512 , chunk_overlap=200 , length_function=len , add_start_index=True , ) paragraphs = text_splitter.create_documents([pages[0 ].page_content]) for para in paragraphs: print (para.page_content) print ('-------' )
1 2 3 4 5 6 7 8 9 10 11 12 13 from langchain_community.document_loaders import TextLoader loader = TextLoader("./meituan-questions.txt" , encoding="utf-8" ) documents = loader.load() print (documents)from langchain_community.document_loaders import DirectoryLoader directLoader = DirectoryLoader("./resource" , glob="**/*.txt" , loader_cls=TextLoader, show_progress=True ) directLoader.load()
切分内容
将整体的文件切分为独立的知识片段。
1 2 3 4 5 6 7 8 9 10 from langchain_text_splitters import CharacterTextSplitter text_splitter = CharacterTextSplitter(chunk_size=512 , chunk_overlap=0 , separator="\n\n" , keep_separator=True ) segments = text_splitter.split_documents(documents) print (len (segments)) for segment in segments: print (segment.page_content)
可以自定义的切分
1 2 3 4 5 6 7 8 9 10 11 import re texts = re.split(r"\n\n" , documents[0 ].page_content) segments = text_splitter.split_text(documents[0 ].page_content) segment_documents = text_splitter.create_documents(segments) print (len (segment_documents)) for segment in segment_documents: print (segment.page_content)
文本向量化(和上面向量数据库部分的操作一样)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 from langchain_community.embeddings import DashScopeEmbeddings embedding_model = DashScopeEmbeddings( model="text-embedding-v1" , ) redis_url = "redis://localhost:6379" from langchain_redis import RedisConfig, RedisVectorStore config = RedisConfig( index_name="meituan-index" , redis_url=redis_url, ) vector_store = RedisVectorStore(embedding_model, config=config) vector_store.add_documents(segment_documents)
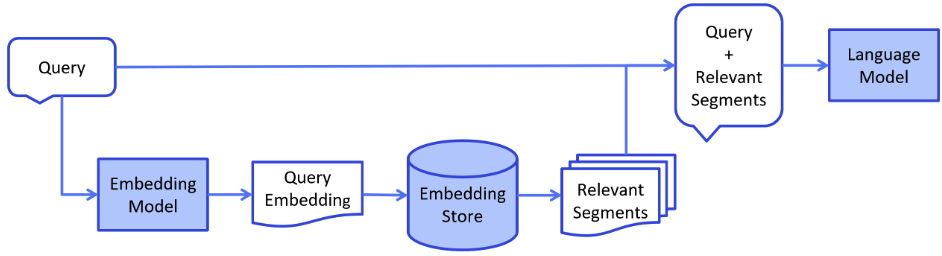
检索增强阶段 用户提出的问题,到向量数据库中检索出关联性较强的 Segment ,再将其和用户的问题整理成完整的 Prompt 发给大模型整合输出。
检索相关信息
1 2 3 4 5 query="在线支付取消订单后钱怎么返还" retriever = vector_store.as_retriever() relative_segments = retriever.invoke(query, k=5 ) print (relative_segments)
构建提示词
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 prompt_template = ChatPromptTemplate.from_messages([ ("user" , """你是一个答疑机器人,你的任务是根据下述给定的已知信息回答用户的问题。 已知信息:{content} 用户问题:{question} 如果已知信息不包含用户问题的答案,或者已知信息不足以回答用户的问题,请直接回复“我无法回答您的问题”。 请不要输出已知信息中不包含的信息或答案。 请用中文回答用户问题。""" ) ]) text = [] for segment in relative_segments: text.append(segment.page_content) prompt = prompt_template.invoke({"context" : text, "question" : query}) print (prompt) prompt_template = ChatPromptTemplate.from_messages([ ("system" , "Translate the following from English into {language}" ), ("user" , "{text}" ) ]) prompt = prompt_template.invoke({"text" : "I love programming." , "language" : "Spanish" }) print (prompt)
调用模型回复
1 2 response = llm.invoke(prompt) print (response.content)
也可以通过 LCEL 语法链来实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 def collect_documents (segments ): text = [] for segment in segments: text.append(segment.content) return text from operator import itemgetter chain = ( { "context" : itemgetter("question" ) | retriever | collect_documents, "question" : itemgetter("question" ) } | prompt_template | llm | StrOutputParser() ) response = chain.invoke({"question" : query}) print (response)