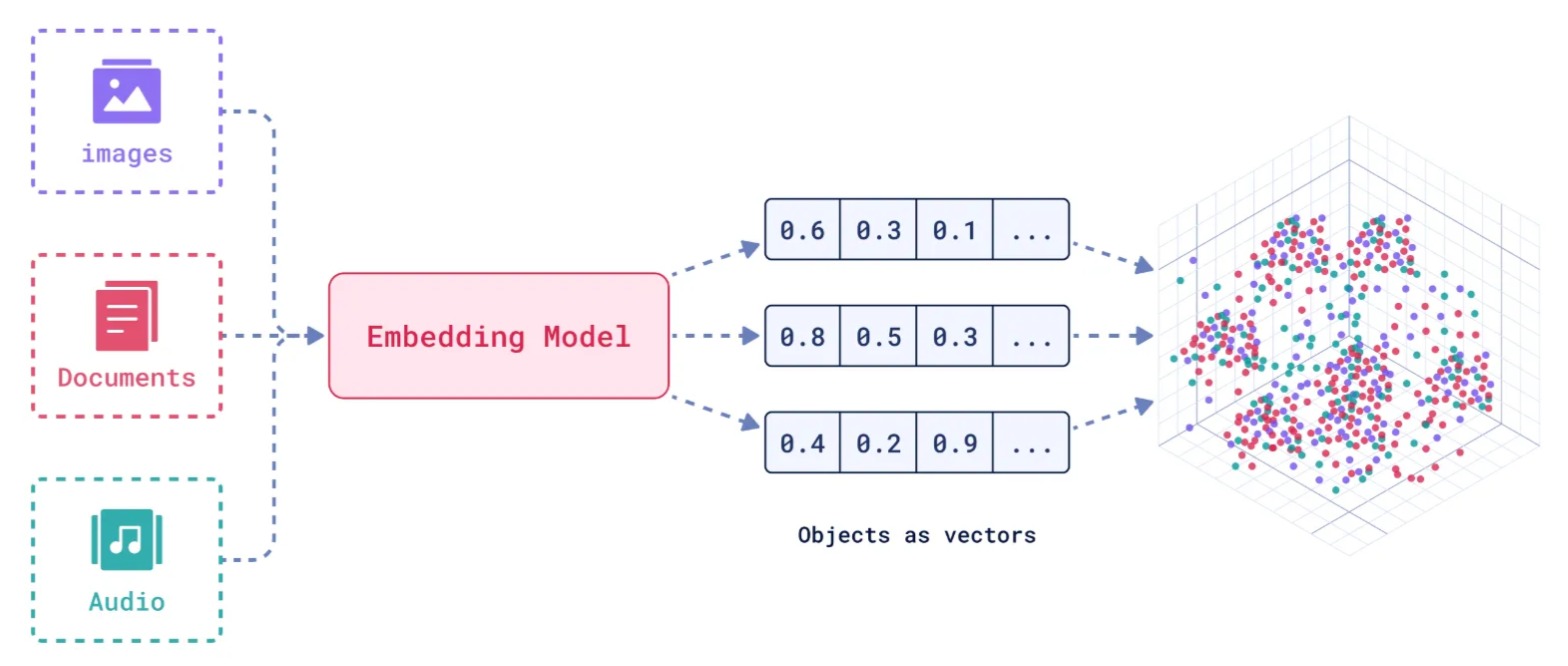
向量表征 向量表征(Vector Representation),将文本、图像、声音、行为等复杂关系化转化为高维向量(Embedding),AI 系统以数学的方式理解和处理现实世界中复杂的信息。
核心思想
降维抽象:将复杂对象映射到低维稠密向量空间,保留关键语义或特征。
相似性度量:向量空间中的距离(如余弦相似度)反应对象之间的语义关联(eg:猫和狗的向量距离小于猫和汽车)。
数学意义
特征工程自动化:传统机器学习依赖人工设计特征(如文本的 TF-IDF),而向量表征通过深度学习自动提取高阶抽象特征。
跨模态通义:文本、图像等不同模态数据可映射到同一向量空间,实现跨模态检索(eg:文字搜索图片)
https://www.sbert.net
通过向量计算得到两个文本之间的相似性关系
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 import osfrom openai import OpenAIclient = OpenAI( api_key=os.getenv("DASHSCOPE_API_KEY" ), base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" ) import numpy as npfrom numpy import dotfrom numpy.linalg import normdef cos_sim (a, b ): '''余弦距离 -- 越大越相似''' return dot(a, b)/(norm(a)*norm(b)) def l2 (a, b ): '''欧氏距离 -- 越小越相似''' x = np.asarray(a)-np.asarray(b) return norm(x)
1 2 3 4 5 6 7 8 9 10 11 12 def get_embeddings (texts, model="text-embedding-v1" , dimensions=None ): '''封装 OpenAI 的 Embedding 模型接口''' if model == "text-embedding-v1" : dimensions = None if dimensions: data = client.embeddings.create( input =texts, model=model, dimensions=dimensions).data else : data = client.embeddings.create(input =texts, model=model).data return [x.embedding for x in data]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 query = "国际争端" documents = [ "联合国就苏丹达尔富尔地区大规模暴力事件发出警告" , "土耳其、芬兰、瑞典与北约代表将继续就瑞典“入约”问题进行谈判" , "日本岐阜市陆上自卫队射击场内发生枪击事件 3人受伤" , "国家游泳中心(水立方):恢复游泳、嬉水乐园等水上项目运营" , "我国首次在空间站开展舱外辐射生物学暴露实验" , ] query_vec = get_embeddings([query])[0 ] doc_vecs = get_embeddings(documents) print ("Query与自己的余弦距离: {:.2f}" .format (cos_sim(query_vec, query_vec)))print ("Query与Documents的余弦距离:" )for vec in doc_vecs: print (cos_sim(query_vec, vec)) print ()print ("Query与自己的欧氏距离: {:.2f}" .format (l2(query_vec, query_vec)))print ("Query与Documents的欧氏距离:" )for vec in doc_vecs: print (l2(query_vec, vec))
Embedding模型 Embedding 通过神经网络或相关大模型,将离散数据(如文本、图像等内容)投影到高维数据空间,根据数据在空间中的不同距离,反应数据在物理世界的相似度。Embedding 模型捕捉数据的语义等各种信息映射至高维向量空间中(高维向量表示)。
主要作用就是转换原始数据、保留上下文信息,同时压缩复杂数据为低维稠密向量,提升存储于计算效率。
关键技术
上下文依赖:现代模型(eg:BGE-M3)动态调整向量,捕捉多义词在不同语境中的含义。
训练方法:对比学习(eg:Word2Vec 的 Skip-gram/CBOW)、预训练+微调(eg: BERT)
主流嵌入模型分类与选型 选型主要考虑因素:
因素
说明
任务性质 匹配任务需求(问答、搜索、聚类等)
领域特性 通用vs专业领域(医学、法律等)
多语言支持 需处理多语言内容时考虑
维度 权衡信息丰富度与计算成本
许可条款 开源vs专有服务
最大Tokens 适合的上下文窗口大小
需要为特定的应用测试选择对应的 Embedding 模型,而非通用模型(不过好像并不是很重要?)
通用全能型:BGE-M3 、NV-Embed-v2
垂直领域特化型:
中文场景: BGE-large-zh-v1.5(合同/政策文件)、M3E-base(社交媒体分析)
多模态场景:BGE-VL (图文跨模态检索),联合编码 OCR 文本与图像特征
轻量化部署型
nomic-embed-text、gte-qwen2-1.5b-instruct
https://huggingface.co/spaces/mteb/leaderboard
Embedding 模型使用 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 import osfrom openai import OpenAIclient = OpenAI( api_key=os.getenv("DASHSCOPE_API_KEY" ), base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" ) completion = client.embeddings.create( model="text-embedding-v3" , input ='国际争端' , dimensions=1024 , encoding_format="float" ) print (completion.model_dump_json())
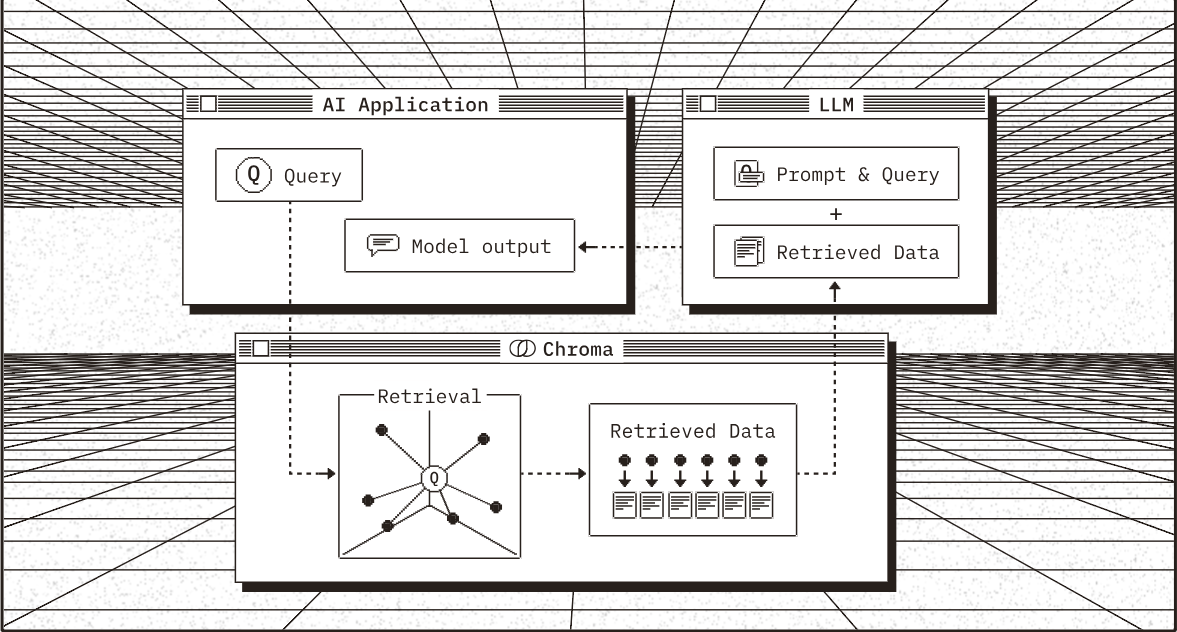
向量数据库 专为高效存储和检索高维向量数据设计。
基于向量距离(如余弦相似度、欧氏距离)衡量数据关联性。
主要功能就是进行向量存储、相似性度量、相似性搜索。
存储:将向量存储为高维空间中的点,并为每个向量分配唯一标识符(ID),同时支持存储元数据。
检索:通过近似最近邻(ANN)算法(如 PQ 等)最向量进行索引和快速1搜索。(通过高效索引结构加速)
向量数据库:Chroma、FAISS、Milvus、Qdrant 、Pinecone、Weaviate、PGVector、RediSearch、ElasticSearch
https://guangzhengli.com/blog/zh/vector-database
Chroma 向量数据库
安装 ChromaDB
初始化客户端
数据临时存放在内存当中,关闭后则丢失。
1 2 import chromadbclient = chromadb.Client()
1 2 client = chromadb.PersistentClient(path="/path/to/save" )
基本操作
主要涉及集合(类似于关系数据库中的一个表)的创建、增加、删除、修改、更新等操作。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 from chromadb.utils import embedding_functions default_ef = embedding_functions.DefaultEmbeddingFunction() openai_ef = embedding_functions.OpenAIEmbeddingFunction( api_key="YOUR_API_KEY" , model_name="text-embedding-3-small" ) collection = client.create_collection( name="my_collection" , configuration={ "hnsw" : { "space" : "cosine" , "ef_search" : 100 , "ef_construction" : 100 , "max_neighbors" : 16 , "num_threads" : 4 }, "embedding_function" : default_ef } ) collection = client.get_collection(name="my_collection" )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 collection.add( documents=["RAG是一种检索增强生成技术" , "向量数据库存储文档的嵌入表示" , "在机器学习领域,智能体(Agent)通常指能够感知环境、做出决策并采取行动以实现特定目标的实体" ], metadatas=[{"source" : "RAG" }, {"source" : "向量数据库" }, {"source" : "Agent" }], ids=["id1" , "id2" , "id3" ] ) collection.add( embeddings = [[0.1 , 0.2 , ...], [0.3 , 0.4 , ...]], documents = ["文本1" , "文本2" ], ids = ["id3" , "id4" ] )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 results = collection.query( query_texts=["RAG是什么?" ], n_results=3 , where = {"source" : "RAG" }, where_document = {"$contains" : "检索增强生成" } ) print (results)results = collection.query( query_embeddings=[[0.5 , 0.6 , ...]], n_results=3 )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 collection.update( ids=["id1" ], documents=["RAG是一种检索增强生成技术,在智能客服系统中大量使用" ] ) updated_docs = collection.get(ids=["doc1" ]) print ("更新后的文档内容:" , updated_docs["documents" ])all_docs = collection.get() print ("集合中所有文档:" , all_docs["documents" ])collection.delete(ids=["doc1" ]) print (collection.peek()) print (collection.count()) print (collection.modify(name="new_name" ))