https://langchain-ai.github.io/langgraph/
Agent 构建简单的问答流程 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 from config.load_key import load_key from langchain_community.chat_models import ChatTongyi llm = ChatTongyi( model="qwen-plus" , api_key=load_key("BAILIAN_API_KEY" ), ) from langgraph.prebuilt import create_react_agent agent = create_react_agent( model=llm, tools=[], prompt="You are a helpful assistant" ) agent.invoke({"messages" : [{"role" : "user" , "content" : "What is the meaning of life?" }]}) for chunk in agent.stream( {"messages" : [{"role" : "user" , "content" : "What is the meaning of life?" }]}, stream_mode="messages" ): print (chunk) print ("\n" )
stream_mode 有三种选项:
updates:流式输出每个工具调用的每个步骤
messages:流式输出大语言模型回复的Token
values:一次拿到所有的 chunk (默认)
custom:自定义输出。可在工具内部使用 get_stream_write 获取输入流,添加自定义内容
1 2 3 4 5 6 7 8 9 10 11 12 import datetime def get_current_date (): """获取今天日期""" return datetime.datetime.today().strftime("%Y-%m-%d" ) agent = create_react_agent( model=llm, tools=[get_current_date], prompt="You are a helpful assistant" ) agent.invoke({"messages" : [{"role" : "user" , "content" : "Time?" }]})
示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 from langchain_core.tools import tool from langgraph.prebuilt import ToolNode @tool("devide_tool" , return_direct=True def devide (a: int , b: int ) -> float : """计算两个整数的除法 Args: a (int): 除数 b (int): 被除数""" if b == 1 : raise ValueError("除数不能为1" ) return a / b print (devide.name) print (devide.description) print (devide.args) def handle_tool_error (error: Exception ) -> str : """处理工具调用错误 Args: error (Exception): 工具调用错误""" if isinstance (error, ValueError): return "除数不能为1" elif isinstance (error, ZeroDivisionError): return "除数不能为0" return f"工具调用错误:{error} " tool_node = ToolNode( [devide], handle_tool_errors=handle_tool_error ) agent_with_error_handler = create_react_agent( model=llm, tools=tool_node, ) result = agent_with_error_handler.invoke({"messages" : [{"role" : "user" , "content" : "10除以5" }]}) print (result["messages" ][-1 ].content) print (result)
增加消息记忆 LangChain 中需自定义 ChatMessageHistory 并自行保存每轮消息记录,在调用模型时,将其作为参数传入。
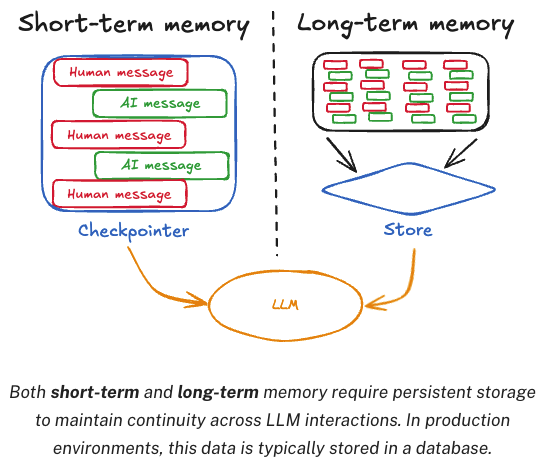
LangGraph 将其封装在了 Agent 中,消息记忆分为长期记忆和短期记忆
短期记忆,Agent 内部的记忆,用当前对话的历史记忆消息。LangGraph 将其封装成 CheckPoint (当前窗口)
长期记忆,Agent 外部的记忆,用第三方存储长久的保存用户级别或应用级别的聊天信息。LangGraph 将其封装成 Store (多个窗口总和)
短期记忆 CheckPoint 在 LangGraph 的 Agent 中,只需要指定 checkpointer 属性,就可以实现短期记忆。具体传⼊的属性需要是 BaseCheckpointSaver 的⼦类。
checkpointer 使用时需要单独指定 thread_id 来区分不同对话
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 from config.load_key import load_key from langchain_community.chat_models import ChatTongyi llm = ChatTongyi( model="qwen-plus" , api_key=load_key("BAILIAN_API_KEY" ), ) from langgraph.checkpoint.memory import InMemorySaver from langgraph.prebuilt import create_react_agent checkpoint = InMemorySaver() def get_weather (city: str ) -> str : """获取某个城市的天气""" return f"城市{city} , 天气挺好" agent = create_react_agent( model=llm, tools=[get_weather], checkpointer=checkpoint, ) config = { "configurable" : { "thread_id" : "1" } } cs_response = agent.invoke( {"messages" : [{"role" : "user" , "content" : "今天在杭州的天气如何?" }]}, config ) print (cs_response) bj_response = agent.invoke( {"messages" : [{"role" : "user" , "content" : "今天在北京的天气如何?" }]}, config ) print (bj_response)
为防止历史消息过多,需要对历史做一定的处理。
LangGraph 的 Agent 中有 pre_model_hook 属性,可以在每次调用大模型之前触发,通过这个 hook 管理短期记忆。
两种管理短期记忆的方式:
Summarization 总结:用大模型的方式,对短期记忆进行总结,然后再把总结结果作为新的短期记忆
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 from langmem.short_term import SummarizationNode from langchain_core.messages.utils import count_tokens_approximately from langgraph.prebuilt import create_react_agent from langgraph.prebuilt.chat_agent_executor import AgentState from langgraph.checkpoint.memory import InMemorySaver from typing import Any summarization_node = SummarizationNode( token_counter=count_tokens_approximately, model=llm, max_tokens=384 , max_summary_tokens=128 , output_messages_key="llm_input_messages" ) class State (AgentState ): context: dict [str , Any ] agent = create_react_agent( model=llm, tools=[get_weather], pre_model_hook=summarization_node, state_schema=State, checkpointer=checkpointer, ) config = {"configurable" : {"thread_id" : "1" }} response = agent.invoke( {"messages" : [{"role" : "user" , "content" : "今天的天气如何?" }]}, config ) print (response["messages" ][-1 ].content)
Trimming 删除:直接把短期记忆中最旧的消息删除
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 from langchain_core.messages.utils import (count_tokens_approximately, trim_messages) from langgraph.prebuilt import create_react_agent def pre_model_hook (state ): trimmed_messages = trim_messages( state["message" ], strategy="last" , token_conter=count_tokens_approximately, max_tokens=1024 , start_on="human" , end_on=("human" , "tool" ) ) return {"llm_input_messages" : trimmed_messages} checkpointer = InMemorySaver() agent = create_react_agent( model=llm, tools=[get_weather], pre_model_hook=pre_model_hook, checkpointer=checkpointer, )
状态管理机制,保存处理过程中的中间结果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 from typing import Annotated from langgraph.prebuilt import InjectedState, create_react_agent from langgraph.prebuilt.chat_agent_executor import AgentState from langchain_core.tools import tool class CustomState (AgentState ): user_id: str @tool(return_direct=True ) def get_user_info (state: Annotated[CustomState, InjectedState] ) -> str : """查询用户信息""" user_id = state["user_id" ] return "user_123 是 Agent" if user_id == "user_123" else "用户不存在" agent = create_react_agent( model=llm, tools=[get_user_info], state_schema=CustomState, ) agent.invoke({ "messages" : "查询用户信息" , "user_id" : "user_123" })
长期记忆 和短期记忆差不多,主要通过 Agent 的 store 属性指定,通过 namespace 来区分不同的命名空间
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 from langchain_core.runnables import RunnableConfig from langgraph.config import get_store from langgraph.prebuilt import create_react_agent from langgraph.store.memory import InMemoryStore from langchain_core.tools import tool store = InMemoryStore() store.put( ("users" ,), "user_123" , { "name" : "Agent" , "age" : "33" } ) @tool(return_direct=True ) def get_user_info (user_id: str ) -> str : """查询用户信息""" store = get_store() user_id = config["configurable" ].get("user_id" ) user_info = store.get(("users" ,), user_id) return str (user_info.value) if user_info else "用户不存在" agent = create_react_agent( model=llm, tools=[get_user_info], store=store, ) agent.invoke( {"messages" : [{"role" : "user" , "content" : "查询用户信息" }]}, config={ "configurable" : {"user_id" : "user_123" } } )
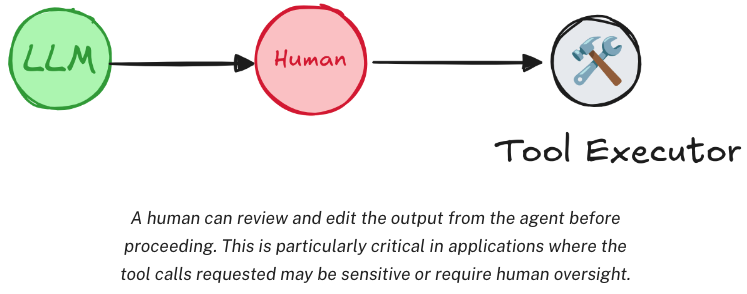
Human-in-the-loop 人类监督 Agent 调用工具完全由其自己决定,Human-in-the-loop 允许在工具调用的过程中用户进行监督。需要中断当前任务,等待用户输入,再重新恢复任务。
interrupt 方法添加人类监督,监督时需要中断当前任务,所以通常是和 stream 流式方法配合使用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 from langgraph.checkpoint.memory import InMemorySaver from langgraph.types import interrupt from langgraph.prebuilt import create_react_agent from langchain_core.tools import tool @tool(return_direct=True ) def book_hotel (hotel_name: str ): """预定宾馆""" response = interrupt( f"正准备执行‘book_hotel’工具预定宾馆,相关参数名:{{'hotel_name': {hotel_name} }}" "请选择OK,表示同意,或edit,提出补充意见。" ) if response["type" ] == "OK" : pass elif response["type" ] == "edit" : hotel_name = response["args" ]["hotel_name" ] else : raise ValueError(f"Unknown response type:{response['type' ]} " ) return f"已预定{hotel_name} 成功" checkpointer = InMemorySaver() agent = create_react_agent( model=llm, tools=[book_hotel], checkpointer=checkpointer, ) config = { "configurable" : { "thread_id" : "1" } } for chunk in agent.stream( {"messages" : [{"role" : "user" , "content" : "帮我在图灵宾馆预定一个房间" }]}, config ): print (chunk) print ("---" )
interrupt 只有在工具即将被执行时才会触发。eg:若 content 的内容是 帮我预定一个宾馆 ,Agent 认为信息不够具体,所以它先询问你想预定哪个酒店,而不是直接调用 book_hotel 工具。则不会触发 interrupt 。
执行完工具后,输出 Interrupt 响应,等待用户输入确认。随后通过提交 Command 请求,继续完成之前的任务。
1 2 3 4 5 6 7 8 9 10 from langgraph.types import Command for chunk in agent.stream( Command(resume={"type" : "edit" , "args" : {"hotel_name" : "Hello宾馆" }}), config ): print (chunk) print (chunk["tools" ]["messages" ][-1 ].content) print ("---" )
Graph 构建 Graph Graph 用来描述任务之间的依赖关系,主要包含三个基本元素:
State:在整个应用中共享的一种数据结构
Node:一个处理数据的节点,通常为一个函数,以 State 作为输入,经过操作后,返回更新后的 State
Edge:表示 Node 之间的依赖关系,通常为一个函数,根据当前 State 来决定接下来执行哪个 Node
示例 1 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 from typing import TypedDict from langgraph.constants import END, START from langgraph.graph import StateGraph class InputState (TypedDict ): user_input: str class OutputState (TypedDict ): graph_output: str class OverallState (TypedDict ): foo: str user_input: str graph_output: str class PrivateState (TypedDict ): bar: str def node_1 (state: InputState ) -> OverallState: return {"foo" : state["user_input" ] + ">学习" } def node_2 (state: OverallState ) -> PrivateState: return {"bar" : state["foo" ] + ">天天" } def node_3 (state: PrivateState ) -> OutputState: return {"graph_output" : state["bar" ] + ">向上" } builder = StateGraph(OverallState, input_schema=InputState, output_schema=OutputState) builder.add_node("node_1" , node_1) builder.add_node("node_2" , node_2) builder.add_node("node_3" , node_3) builder.add_edge(START, "node_1" ) builder.add_edge("node_1" , "node_2" ) builder.add_edge("node_2" , "node_3" ) builder.add_edge("node_3" , END) graph = builder.compile () graph.invoke({"user_input" : "hello" })
示例 2 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 from typing import Annotated from typing_extensions import TypedDict from langgraph.graph import StateGraph, START, END from langgraph.graph.message import add_messages class State (TypedDict ): messages: Annotated[list , add_messages] graph_builder = StateGraph(State) from langchain.chat_models import init_chat_modelllm = init_chat_model("gpt-4o" , model_provider="openai" ) def chatbot (state: State ): return {"messages" : [llm.invoke(state["messages" ])]} graph_builder.add_node("chatbot" , chatbot) graph_builder.add_edge(START, "chatbot" ) graph_builder.add_edge("chatbot" , END) graph = graph_builder.compile () from langchain.schema import AIMessagedef stream_graph_updates (user_input: str ): for event in graph.stream({"messages" : [{"role" : "user" , "content" : user_input}]}): for value in event.values(): if "messages" in value and isinstance (value["messages" ][-1 ], AIMessage): print ("Assistant:" , value["messages" ][-1 ].content) def run (): while True : user_input = input ("User: " ) if user_input.strip() == "" : break stream_graph_updates(user_input) run()
1 2 3 4 5 6 7 8 9 10 from IPython.display import Image, displaytry : display(Image(data=graph.get_graph().draw_mermaid_png())) except Exception as e: print (e)
State 状态 State 所有节点共享的状态,一个字典,包含了所有节点的状态
State 形式上,可以是 TypedDict 字典,也可以是 Pydantic 中的一个 BaseModel (本质上没有太多区别)。eg:
1 2 3 4 from pydantic import BaseModelclass OverallState (BaseModel ): a: str
State 中定义的属性,通常不需要指定默认值,若需要默认值,可通过在 START 节点后,定义一个 node 来指定。eg:
1 2 def node (state: OverallState ): return {"a" : "goodbye" }
State 中的属性,除了可修改值外,也可以定义一些操作,来指定如何更新 State 中的值。eg:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 from langgraph.graph.message import add_messages from typing import TypedDict, Annotated, List from langchain_core.messages import AnyMessage from operator import add class State (TypedDict ): messages: Annotated[list [AnyMessage], add_messages] list_field: Annotated[list [int ], add] extra_field: str
此时,若有一个 node ,返回了 State 中更新的值,那么 messages 和 list_fild 的值就会添加到原有的旧集合中,而 extra_field 的值会被替换。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 from langgraph.graph import StateGraph from langgraph.graph.message import add_messages from typing import TypedDict, Annotated from langchain_core.messages import AnyMessage, AIMessage from operator import add from langchain_core.messages import HumanMessage class State (TypedDict ): messages: Annotated[list [AnyMessage], add_messages] list_field: Annotated[list [int ], add] extra_field: str def node1 (state: State ): new_message = AIMessage("Hello!" ) return {"messages" : [new_message], "list_field" : [10 ], "extra_field" : 10 } def node2 (state: State ): new_message = AIMessage("LangGraph!" ) return {"messages" : [new_message], "list_field" : [20 ], "extra_field" : 20 } graph = (StateGraph(State) .add_node("node1" , node1) .add_node("node2" , node2) .set_entry_point("node1" ) .add_edge("node1" , "node2" ) .compile ()) input_message = HumanMessage(content="Hi!" ) result = graph.invoke({"messages" : [input_message], "list_field" : [1 , 2 , 3 ]}) print (result) for message in result["messages" ]: message.pretty_print() print (result["extra_field" ])
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 执行流程分析: 1. 初始状态: messages: [{"role": "user", "content": "Hi!"}] list_field: [1, 2, 3] extra_field: undefined 2. node1执行后: messages: [{"role": "user", "content": "Hi!"}, AIMessage("Hello!")] list_field: [1, 2, 3, 10] extra_field: 10 3. node2执行后: messages: [{"role": "user", "content": "Hi!"}, AIMessage("Hello!"), AIMessage("LangGraph!")] list_field: [1, 2, 3, 10, 20] extra_field: 20 最终输出result包含所有这些字段
State 通常都会保存聊天消息,LangGraph 中 langgraph.graph.MessagesState 可以用来快速保存消息
1 2 class MessagesState (TypedDict ): messages: Annotated[list [AnyMessage], add_messages]
对于 Messages 可以用两种方式来声明:
1 2 3 {"messages" : [HumanMessage(content="message" )]} {"messages" : [{"type" : "user" , "content" : "message" }]}
Node 节点 Node 图中处理数据的节点
Node 通常为一个函数,接收一个 State 对象输入,返回一个 State 输出
每个 Node 都有唯一名称,通常为一个字符串,若没有提供名称,LangGraph 会自动生成一个和函数名相同的名称
通常包含两个具体参数,State 必选,配置项 config 可选 ,包含一些节点运行的配置参数
每个 Node 都有缓存机制,只要 Node 传入参数相同,LangGraph 就会优先从缓存中获取执行结果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 import time from typing import TypedDict from langchain_core.runnables import RunnableConfig from langgraph.constants import START, END from langgraph.graph import StateGraph from langgraph.types import CachePolicy from langgraph.cache.memory import InMemoryCache class State (TypedDict ): number: int user_id: str class ConfigSchema (TypedDict ): user_id: str def node_1 (state: State, config: RunnableConfig ): time.sleep(3 ) user_id = config["configurable" ]["user_id" ] return {"number" : state["number" ] + 1 , "user_id" : user_id} builder = StateGraph(State, config_schema=ConfigSchema) builder.add_node("node_1" , node_1, cache_policy=CachePolicy(ttl=5 )) builder.add_edge(START, "node_1" ) builder.add_edge("node_1" , END) graph = builder.compile (cache=InMemoryCache()) print (graph.invoke({"number" : 5 }, config={"configurable" : {"user_id" : "123" }}, stream_mode="updates" )) print (graph.invoke({"number" : 5 }, config={"configurable" : {"user_id" : "456" }}, stream_mode="updates" ))
除了缓存机制,还提供了重试机制,可针对单个节点指定,eg:
1 2 3 from langgraph.types import RetryPolicybuilder.add_node("nodel" , node_1, retry=RetryPolicy(max_attempts=4 ))
也可针对某一次任务调用指定,eg:
1 print (graph.invoke(xxxx, config={"recursion_limit" : 25 }))
Edge 边 通过 Edge 把 Node 连接起来,从而决定 State 应该如何在 Graph 中传递。
1 2 3 builder = StateGraph(State) builder.set_entry_point("node_1" ) builder.set_finish_point("node_2" )
添加带有条件判断的 Edge 和 EntryPoint ,用来动态构建更复杂的工作流程。具体可以指定一个函数,函数返回值就可以是下一个 Node 的名称
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 from typing import TypedDict from langchain_core.runnables import RunnableConfig from langgraph.constants import START, END from langgraph.graph import StateGraph class State (TypedDict ): number: int def node_1 (state: State, config: RunnableConfig ): return {"number" : state["number" ] + 1 } builder = StateGraph(State) builder.add_node("node_1" , node_1) def routing_func (state: State ) -> str : if state["number" ] > 5 : return "node_1" else : return END builder.add_edge("node_1" , END) builder.add_conditional_edges(START, routing_func) graph = builder.compile () print (graph.invoke({"number" : 6 }))
若不想再路由函数中写入过多具体节点名称,可以在函数返回中自定义结果,然后将该结果解析到某一具体 Node 上。eg:
1 2 3 4 5 6 7 8 def routing_func (state: State ) -> bool : if state["number" ] > 5 : return True else : return False builder.add_conditional_edges(START, routing_func, {True : "node_a" , False : "node_b" })
在条件边种,若希望一个 Node 后同时路由到多个 Node ,则可以返回 Send 动态路由的方式实现。Send 对象可传入两个参数,第一个是下一个 Node 的名称,第二个是 Node 的输入。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 from operator import add from typing import TypedDict, Annotated from langgraph.constants import START, END from langgraph.graph import StateGraph from langgraph.types import Send class State (TypedDict ): messages: Annotated[list [str ], add] class PrivateState (TypedDict ): msg: str def node_1 (state: PrivateState ) -> State: res = state["msg" ] + "!" return {"messages" : [res]} builder = StateGraph(State) builder.add_node("node_1" , node_1) def routing_func (state: State ): result = [] for message in state["messages" ]: result.append(Send("node_1" , {"msg" : message})) return result builder.add_conditional_edges(START, routing_func, ["node_1" ]) builder.add_edge("node_1" , END) graph = builder.compile () print (graph.invoke({"messages" : ["hello" , "world" , "hello" , "graph" ]}))
Graph 典型业务步骤是 State 进入一个 Node 处理,在 Node 中先更新 State 状态,再通过 Edges 传递给下一个 Node ,若希望将这两个步骤合并为一个命令,则可以使用 Command 命令。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 from operator import add from typing import TypedDict, Annotated from langgraph.constants import START, END from langgraph.graph import StateGraph from langgraph.types import Command class State (TypedDict ): messages: Annotated[list [str ], add] def node_1 (state: State ): new_messages = [] for message in state["messages" ]: new_messages.append(message + "!" ) return Command( goto=END, update={"messages" : new_messages}, ) builder = StateGraph(State) builder.add_node("node_1" , node_1) builder.add_edge(START, "node_1" ) graph = builder.compile () print (graph.invoke({"messages" : ["hello" , "world" , "hello" , "graph" ]}))
子图 一个 Graph 可以单独使用,也可以作为一个 Node 嵌入到另一个 Graph 中。子图的使用和 Node 没太多区别,只是当触发 SubGraph 代表的 Node 后,实际上是相当于重新调用了一个 subgraph.invoke(state) 方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 from operator import add from typing import TypedDict, Annotated from langgraph.constants import END from langgraph.graph import StateGraph, MessagesState, START from langgraph.types import Command class State (TypedDict ): messages: Annotated[list [str ], add] def sub_node_1 (state: State ) -> MessagesState: return {"messages" : ["response from subgraph" ]} subgraph_builder = StateGraph(State) subgraph_builder.add_node("sub_node_1" , sub_node_1) subgraph_builder.add_edge(START, "sub_node_1" ) subgraph_builder.add_edge("sub_node_1" , END) subgraph = subgraph_builder.compile () builder = StateGraph(State) builder.add_node("subgraph_node" , subgraph) builder.add_edge(START, "subgraph_node" ) builder.add_edge("subgraph_node" , END) graph = builder.compile () print (graph.invoke({"messages" : ["hello subgraph" ]}))
图的 Stream 支持 stream 流式调用,依次返回 State 数据处理步骤。stream()同步流式调用,astream()异步流式调用
1 2 for chunk in graph.stream({"messages" : ["hello subgraph" ]}, stream_mode="debug" ): print (chunk)
几种不同的 stream_mode:
value:在图的每一步之后流式传输状态的完整值
updates:在图的每一步之后,将更新内容流式传输到状态,若在统一步骤中进行多次更新(eg:运行了多个节点),这些更新将分别进行流式传输
custom:从图节点内部流式传输自定义数据,通常用于调试
messages:从任何大模型的图节点中,流式传输二元组(LLM 的 Token,元数据)
debug:在图执行过程中尽可能多地传输信息
custom 模式,可以自定义输出内容,在 Node 节点或 Tools 工具内,通过 get_stream_writer() 获取一个 StreamWrite 对象,然后用 write() 将自定义数据写入流中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 from typing import TypedDict from langgraph.config import get_stream_writer from langgraph.graph import StateGraph, START class State (TypedDict ): query: str answer: str def node (state: State ): writer = get_stream_writer() writer({"自定义key" : "在节点内返回自定义信息" }) return {"answer" : "some data" } graph = ( StateGraph(State) .add_node("node" , node) .add_edge(START, "node" ) .add_edge("node" , END) .compile () ) inputs = {"query" : "hello" } for chunk in graph.stream(inputs, stream_mode="custom" ): print (chunk)
构建 LLM 对象时,支持通过 disable_streaming 禁止流式输出
1 llm = ChatOpenAI(model="" , disable_streaming=True )
messages 模式,监控大模型 Token 记录
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 from config.load_key import load_key from langchain_community.chat_models import ChatTongyi llm = ChatTongyi( model="qwen-plus" , api_key=load_key("BAILIAN_API_KEY" ), ) from langgraph.graph import StateGraph, MessagesState, START def call_model (state: MessagesState ): response = llm.invoke(state["messages" ]) return {"messages" : response} builder = StateGraph(MessagesState) builder.add_node("call_model" , call_model) builder.add_edge(START, "call_model" ) graph = builder.compile () for chunk in graph.stream( {"messages" : [{"role" : "user" , "content" : "美国的首都是哪里" }]}, stream_mode="messages" ): print (chunk)
大模型消息持久化 Graph 和 Agent 的相似,都支持 checkpointer 构建短期记忆,store 构建长期记忆
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 from config.load_key import load_key from langchain_community.chat_models import ChatTongyi llm = ChatTongyi( model="qwen-plus" , api_key=load_key("BAILIAN_API_KEY" ), ) from langgraph.graph import StateGraph, MessagesState, START from langgraph.checkpoint.memory import InMemorySaver def call_model (state: MessagesState ): response = llm.invoke(state["messages" ]) return {"messages" : response} builder = StateGraph(MessagesState) builder.add_node("call_model" , call_model) builder.add_edge(START, "call_model" ) checkpointer = InMemorySaver() graph = builder.compile (checkpointer=checkpointer) config = { "configurable" : { "thread_id" : "1" } } for chunk in graph.stream( {"messages" : [{"role" : "user" , "content" : "中国最好的大学是哪一所?" }]}, config, stream_mode="values" , ): chunk["messages" ][-1 ].pretty_print() for chunk in graph.stream( {"messages" : [{"role" : "user" , "content" : "美国呢?" }]}, config, stream_mode="values" , ): chunk["messages" ][-1 ].pretty_print()
Human-in-loop 人类干预 基本流程:
指定 checkpointer 短期记忆,保存任务状态
指定 thread_id 配置项,指定线程 ID ,便于之后通过线程 ID ,指定恢复线程
任务执行过程,通过 Interrupt 终端任务,等待确认
确认后,通过提交一个带有 resume=True 的 Command 指令,恢复任务,并继续执行
示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 from config.load_key import load_key from langchain_community.chat_models import ChatTongyi llm = ChatTongyi( model="qwen-plus" , api_key=load_key("BAILIAN_API_KEY" ), ) from operator import add from langchain_core.messages import AnyMessage from langgraph.constants import START, END from langgraph.graph import StateGraph from langgraph.checkpoint.memory import InMemorySaver from typing import Literal , TypedDict, Annotated from langgraph.types import interrupt, Command class State (TypedDict ): messages: Annotated[list [AnyMessage], add] def human_approval (state: State ) -> Command[Literal ["call_llm" , END]]: is_approved = interrupt( { "question" : "是否同意调用大语言模型?" } ) if is_approved: return Command(goto="call_llm" ) else : return Command(goto=END) def call_llm (state: State ): response = llm.invoke(state["messages" ]) return {"messages" : [response]} builder = StateGraph(State) builder.add_node("human_approval" , human_approval) builder.add_node("call_llm" , call_llm) builder.add_edge(START, "human_approval" ) checkpointer = InMemorySaver() graph = builder.compile (checkpointer=checkpointer) from langchain_core.messages import HumanMessage thread_config = {"configurable" : {"thread_id" : 1 }} graph.invoke({"messages" : [HumanMessage(content="What is the meaning of life?" )]}, config=thread_config) final_result = graph.invoke(Command(resume=True ), config=thread_config) print (final_result)
任务中断和恢复,需要保持相同的 thread_id ,通常会随机生成
中断任务的时间不能过长,过长了之后就无法恢复
Command 中传递的 resume 可以是简单的 True 或 False ,也可以是⼀个字典。通过字典可以进行更多的判断。
Time Travel 时间回溯 时间回溯,保存 Graph 运行过程,手动指定从 Graph 的某一个 Node 开始进行重演。
运行时,需要提供初始输入消息
指定线程ID
指定 thread_id 和 check_point_id ,进行任务重演,重演钱,可选择更新 state。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 from config.load_key import load_key from langchain_community.chat_models import ChatTongyi llm = ChatTongyi( model="qwen-plus" , api_key=load_key("BAILIAN_API_KEY" ), ) from typing import TypedDict from typing_extensions import NotRequired from langgraph.checkpoint.memory import InMemorySaver from langgraph.constants import START, END from langgraph.graph import StateGraph class State (TypedDict ): author: NotRequired[str ] joke: NotRequired[str ] def author_node (state: State ): prompt = "帮我推荐⼀位受⼈们欢迎的作家。只需要给出作家的名字即可。" author = llm.invoke(prompt) return {"author" : author} def joke_node (state: State ): prompt = f"⽤作家:{state['author' ]} 的⻛格,写⼀个100字以内的笑话" joke = llm.invoke(prompt) return {"joke" : joke} builder = StateGraph(State) builder.add_node(author_node) builder.add_node(joke_node) builder.add_edge(START, "author_node" ) builder.add_edge("author_node" , "joke_node" ) builder.add_edge("joke_node" , END) checkpointer = InMemorySaver() graph = builder.compile (checkpointer=checkpointer) import uuid config = { "configurable" : { "thread_id" : uuid.uuid4(), } } state = graph.invoke({}, config) print (state["author" ]) print () print (state["joke" ])
1 2 3 4 5 6 7 states = list (graph.get_state_history(config)) for state in states: print (state.next ) print (state.config["configurable" ]["checkpoint_id" ]) print (state.values) print ()
1 2 3 4 selected_state = states[1 ] print (selected_state.next ) print (selected_state.values)
1 2 3 new_config = graph.update_state(selected_state.config, values={"author" : "郭德纲" }) print (new_config)
1 2 graph.invoke(None , new_config)
构建 RAG 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 from langchain_community.embeddings import DashScopeEmbeddings from langchain_text_splitters import RecursiveCharacterTextSplitter from langchain_community.vectorstores import FAISS from langchain_community.document_loaders import PyMuPDFLoader loader = PyMuPDFLoader("./data/deepseek-v3-1-4.pdf" ) pages = loader.load_and_split() text_splitter = RecursiveCharacterTextSplitter( chunk_size=512 , chunk_overlap=200 , length_function=len , add_start_index=True , ) texts = text_splitter.create_documents( [page.page_content for page in pages[:2 ]] ) embeddings = DashScopeEmbeddings(model="text-embedding-v1" ) db = FAISS.from_documents(texts, embeddings) retriever = db.as_retriever(search_kwargs={"k" : 5 }) from langchain.prompts import ChatPromptTemplate, HumanMessagePromptTemplate template = """请根据对话历史和下面提供的信息回答上面用户提出的问题: {query} """ prompt = ChatPromptTemplate.from_messages( [ HumanMessagePromptTemplate.from_template(template), ] ) def retrieval (state: State ): user_query = "" if len (state["messages" ]) >= 1 : user_query = state["messages" ][-1 ] else : return {"messages" : []} docs = retriever.invoke(str (user_query)) messages = prompt.invoke("\n" .join([doc.page_content for doc in docs])).messages return {"messages" : messages} def chatbot (state: State ): graph_builder = StateGraph(State) graph_builder.add_node("retrieval" , retrieval) graph_builder.add_node("chatbot" , chatbot) graph_builder.add_edge(START, "retrieval" ) graph_builder.add_edge("retrieval" ,"chatbot" ) graph_builder.add_edge("chatbot" , END) graph = graph_builder.compile () from langchain.schema import AIMessage def stream_graph_updates (user_input: str ): for event in graph.stream({"messages" : [{"role" : "user" , "content" : user_input}]}): for value in event.values(): if "messages" in value and isinstance (value["messages" ][-1 ], AIMessage): print ("Assistant:" , value["messages" ][-1 ].content) def run (): while True : user_input = input ("User: " ) if user_input.strip() == "" : break stream_graph_updates(user_input) run()
加入分支 若找不到答案则转人工处理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 from langchain.schema import HumanMessage from typing import Literal from langgraph.types import interrupt, Command def verify (state: State ) -> Literal ["chatbot" , "ask_human" ]: message = HumanMessage( "请根据对话历史和上面提供的信息判断,已知的信息是否能够回答用户的问题。直接输出你的判断'Y'或'N'" ) ret = llm.invoke(state["messages" ] + [message]) if 'Y' in ret.content: return "chatbot" else : return "ask_human" def ask_human (state: State ): user_query = state["messages" ][-2 ].content human_response = interrupt( { "question" : user_query } ) return { "messages" : [AIMessage(human_response)] } from langgraph.checkpoint.memory import MemorySavermemory = MemorySaver() graph_builder = StateGraph(State) graph_builder.add_node("retrieval" , retrieval) graph_builder.add_node("chatbot" , chatbot) graph_builder.add_node("ask_human" , ask_human) graph_builder.add_edge(START, "retrieval" ) graph_builder.add_conditional_edges("retrieval" , verify) graph_builder.add_edge("ask_human" , END) graph_builder.add_edge("chatbot" , END) graph = graph_builder.compile (checkpointer=memory) from langchain.schema import AIMessagethread_config = {"configurable" : {"thread_id" : "my_thread_id" }} def stream_graph_updates (user_input: str ): for event in graph.stream( {"messages" : [{"role" : "user" , "content" : user_input}]}, thread_config ): for value in event.values(): if isinstance (value, tuple ): return value[0 ].value["question" ] elif "messages" in value and isinstance (value["messages" ][-1 ], AIMessage): print ("Assistant:" , value["messages" ][-1 ].content) return None return None def resume_graph_updates (human_input: str ): for event in graph.stream( Command(resume=human_input), thread_config, stream_mode="updates" ): for value in event.values(): if "messages" in value and isinstance (value["messages" ][-1 ], AIMessage): print ("Assistant:" , value["messages" ][-1 ].content) def run (): while True : user_input = input ("User: " ) if user_input.strip() == "" : break question = stream_graph_updates(user_input) if question: human_answer = input ("Ask Human: " + question + "\nHuman: " ) resume_graph_updates(human_answer) run()
1 graph TD; A[__start__] --> B[retrieval]; B -->|ask_human| C[ask_human]; B -->|chatbot| D[chatbot]; C --> E[__end__]; D --> E;