1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
| import asyncio
import os
from operator import add
from typing import TypedDict, Annotated
import redis
from langchain_redis import RedisConfig, RedisVectorStore
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_core.prompts import ChatPromptTemplate
from langgraph.prebuilt import create_react_agent
from langchain_community.chat_models import ChatTongyi
from langchain_core.messages import AnyMessage, HumanMessage, AIMessage
from langchain_mcp_adapters.client import MultiServerMCPClient
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.config import get_stream_writer
from langgraph.constants import START, END
from langgraph.graph import StateGraph
from config.load_key import load_key
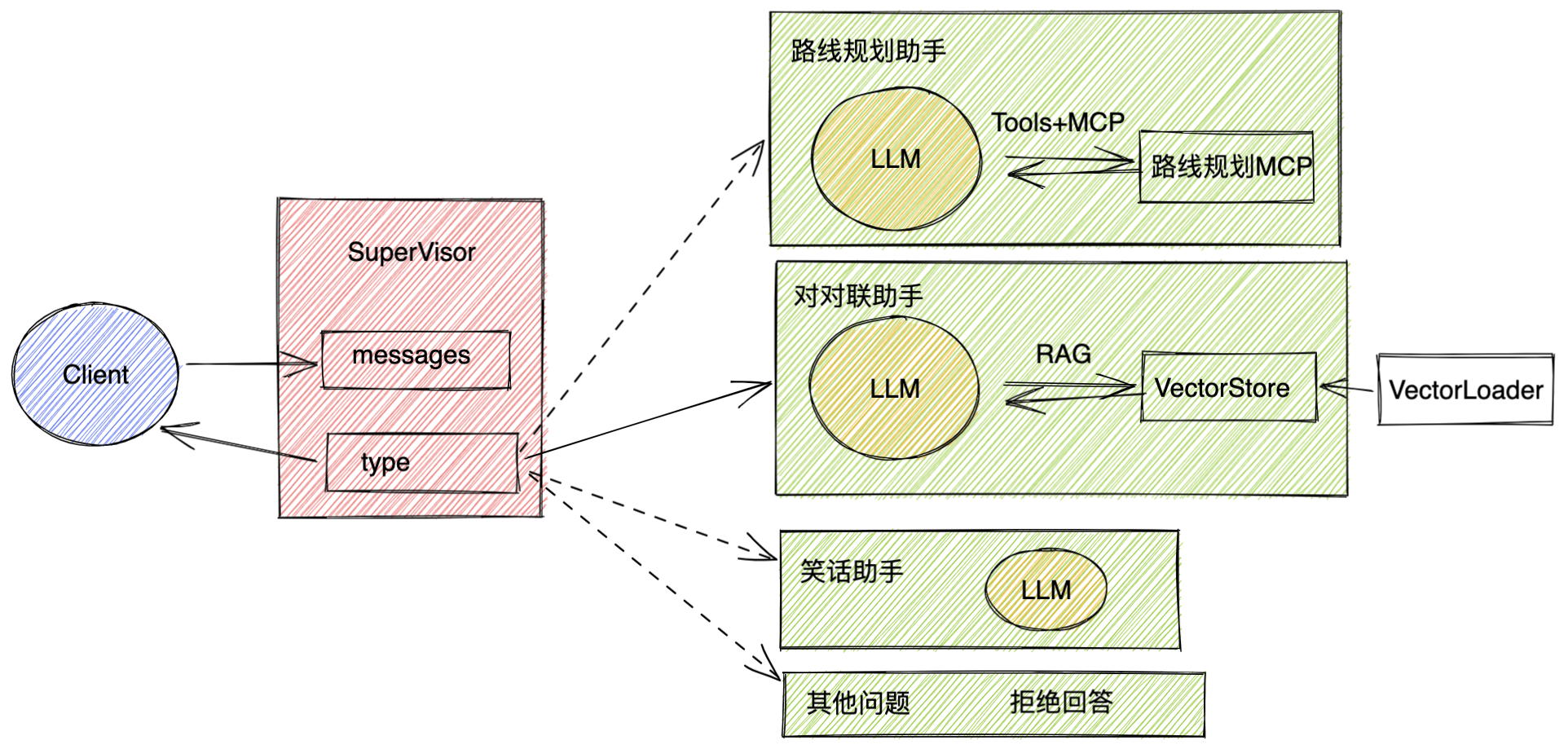
nodes = ["supervisor", "travel", "joke", "couplet", "other", END]
llm = ChatTongyi(
model="qwen-plus",
api_key=load_key("BAILIAN_API_KEY"),
)
class State(TypedDict):
messages: Annotated[list[AnyMessage], add]
type: str
def supervisor_node(state: State):
'''
主管节点:负责对用户问题进行分类并路由到相应处理节点
:param state:
:return:
'''
print(">>> supervisor_node")
writer = get_stream_writer()
writer({"node", ">>> supervisor_node"})
prompt = """你是一个专业的客服助手,负责对用户的问题进行分类,并将任务分给其他Agent执行。
如果用户问题是和旅游路线规划相关的,那就返回 travel;
如果用户问题是希望讲一个笑话,那就返回 joke;
如果用户的问题是对一个对联,那就返回 couplet;
如果是其他的问题,返回 other;
除了这几个选项外,不要返回任何其他的内容。
"""
prompts = [
{"role": "system", "content": prompt},
{"role": "user", "content": state["messages"][0]}
]
if "type" in state:
writer({"supervisor_step", f"已经获得{state['type']}智能体处理结果"})
return {"type": END}
else:
response = llm.invoke(prompts)
typeRes = response.content
writer({"supervisor_step": f"问题分类结果:{typeRes}"})
if typeRes in nodes:
return {"type": typeRes}
else:
raise ValueError("type is not in types_node")
def travel_node(state: State):
'''
旅游路线规划节点:处理旅游相关问题
:param state:
:return:
'''
print(">>> travel_node")
writer = get_stream_writer()
writer({"node": ">>> travel_node"})
system_prompt = "你是一个专业的旅行规划助手,根据用户的输入,生成一个50字左右的路线规划。"
prompts = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": state["messages"][0]}
]
client = MultiServerMCPClient(
{
"amap-maps": {
"command": "npx",
"args": [
"-y",
"@amap/amap-maps-mcp-server"
],
"env": {
"AMAP_MAPS_API_KEY": "451ad40d0e39453600f2a305e31eabe4"
},
"transport": "stdio"
}
}
)
tools = asyncio.run(client.get_tools())
agent = create_react_agent(
model=llm,
tools=tools
)
response = agent.invoke({"messages": prompts})
writer({"travel_result": response["messages"][-1].content})
return {"messages": [HumanMessage(content=response["messages"][-1].content)], "type": "travel"}
def joke_node(state: State):
'''
笑话生成节点:处理笑话请求
:param state:
:return:
'''
print(">>> joke_node")
writer = get_stream_writer()
writer({"node": ">>> joke_node"})
system_prompt = "你是一个笑话大师,根据用户的输入,生成一个5字左右的笑话。"
prompts = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": state["messages"][0]}
]
response = llm.invoke(prompts)
writer({"joke_result": response.content})
return {"messages": [AIMessage(content=response.content)], "type": "joke"}
def couplet_node(state: State):
'''
对联生成节点:处理对联请求
:param state:
:return:
'''
print(">>> couplet_node")
writer = get_stream_writer()
writer({"node": ">>> couplet_node"})
prompt_template = ChatPromptTemplate.from_messages([
("system", """
你是一个专业的对联大师,你的任务是根据用户给出的上联,设计下联
回答时,可以参考下面对联
参考对联:
{samples}
请用中文回答问题
"""),
("user", "{text}")
])
query = state["messages"][0]
if not os.environ.get("DASHSCOPE_API_KEY"):
os.environ["DASHSCOPE_API_KEY"] = load_key("BAILIAN_API_KEY")
embedding_model = DashScopeEmbeddings(model="text-embedding-v1")
redis_url = "redis://localhost:6379"
redis_client = redis.from_url(redis_url)
print(redis_client.ping())
config = RedisConfig(
index_name="couplet",
redis_client=redis_client,
)
vector_store = RedisVectorStore(embedding_model, config)
samples = []
scored_results = vector_store.similarity_search(query, k=10)
for doc, score in scored_results:
samples.append(doc.page_content)
prompt = prompt_template.invoke({"samples": samples, "text": query})
writer({"couplet_prompt": prompt})
response = llm.invoke(prompt)
writer({"couplet_result": response.content})
return {"messages": [HumanMessage(content=response.content)], "type": "couplet"}
def other_node(state: State):
'''
其他问题处理节点:处理无法分类的问题
:param state:
:return:
'''
print(">>> other_node")
writer = get_stream_writer()
writer({"node": ">>> other_node"})
return {"messages": [HumanMessage(content="我暂时无法回答此问题,请稍后再试。")], "type": "other"}
def routing_func(state: State):
'''
路由函数:根据问题类型决定下一步执行哪个节点
:param state:
:return:
'''
if state["type"] == "travel":
return "travel_node"
elif state["type"] == "joke":
return "joke_node"
elif state["type"] == "couplet":
return "couplet_node"
elif state["type"] == END:
return END
else:
return "other_node"
builder = StateGraph(State)
builder.add_node("supervisor_node", supervisor_node)
builder.add_node("travel_node", travel_node)
builder.add_node("joke_node", joke_node)
builder.add_node("couplet_node", couplet_node)
builder.add_node("other_node", other_node)
builder.add_edge(START, "supervisor_node")
builder.add_conditional_edges("supervisor_node", routing_func,
["travel_node", "joke_node", "couplet_node", "other_node", END])
builder.add_edge("travel_node", "supervisor_node")
builder.add_edge("joke_node", "supervisor_node")
builder.add_edge("couplet_node", "supervisor_node")
builder.add_edge("other_node", "supervisor_node")
checkpointer = InMemorySaver()
graph = builder.compile(checkpointer=checkpointer)
if __name__ == "__main__":
config = {
"configurable": {
"thread_id": "1"
}
}
for chunk in graph.stream({"messages": ["给我一个对联下联,上联是:金榜题名时"]},
config,
stream_mode="custom"
):
print(chunk)
|