Huggingface&Transformers
piplines
pipeline()函数,transformers 中的一个高级 API ,主要用于快速加载预训练模型并执行常见任务(如文本分类、翻译、问答等)。封装了预训练模型和对应的前处理和后处理环节。
常用的 pipelines :
feature-extraction(获得文本的向量化表示)fill-mask(填充被遮盖的词、片段)ner(命名实体识别)question-answering(自动问答)sentiment-analysis(情感分析)summarization(自动摘要)text-generation(文本生成)translation(机器翻译)zero-shot-classification(零训练样本分类)
示例:
1 | # 情感分析 |
1 | No model was supplied, defaulted to distilbert-base-uncased-finetuned-sst-2-english (https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english) |
pipeline 会自动选择合适的预训练模型来完成任务;
- pipeline 自动完成以下步骤:
- 预处理(preprocessing),将原始文本转换为模型可以理解的输入格式;
- 将预处理好的文本送入模型;
- 对模型的预测值进行后处理(postprocessing),输出人类可以理解的格式;
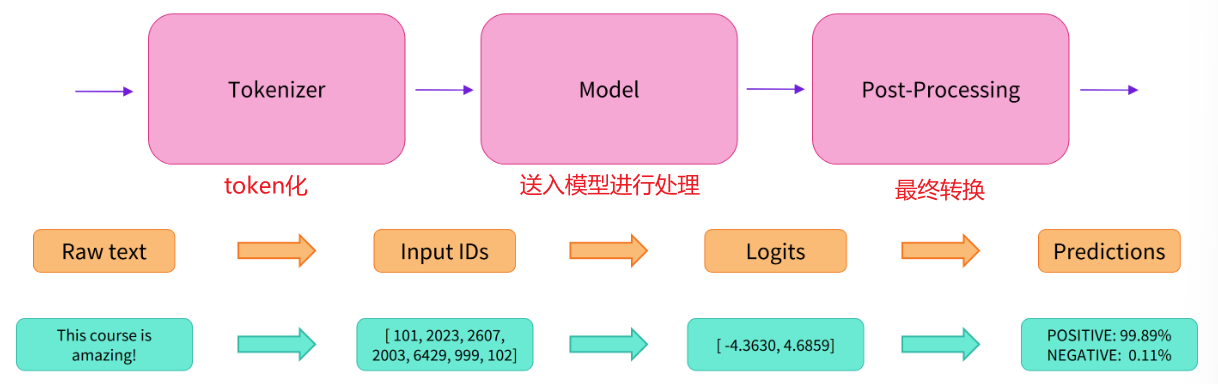
- 预处理:
- 将输入切分为词语、字词或符号,即 tokens;
- 根据模型的词表将每个 token 映射到对应的 token 编号;
- 根据模型需要,添加额外输入;
对于输入文本的预处理需要与模型自身预处理操作完全一致,这样模型才能正常工作;每个模型都有特定的预处理操作,通过 Model Hub 查询;这里使用 AutoTokenizer 类和它的 from_pretrained() 函数,它可以自动根据模型 checkpoint 名称来获取对应的分词器;
示例:这里以默认的情感分析模型为例;
1 | '''使用分词进行预处理''' |
1 | { |
预训练模型的本体只包含基础的 Transformer 模块,对于给定的输入,它会输出一些神经元的值,称为 hidden states 或者特征 (features)。对于 NLP 模型来说,可以理解为是文本的高维语义表示。这些 hidden states 通常会被输入到其他的模型部分(称为 head),以完成特定的任务,例如送入到分类头中完成文本分类任务。
所有 pipelines 都具有类似的模型结构,只是模型的最后一部分会使用不同的 head 以完成对应的任务。
Transformers 库封装了很多不同的结构,常见的有:
*Model(返回 hidden states)*ForCausalLM(用于条件语言模型)*ForMaskedLM(用于遮盖语言模型)*ForMultipleChoice(用于多选任务)*ForQuestionAnswering(用于自动问答任务)*ForSequenceClassification(用于文本分类任务)*ForTokenClassification(用于 token 分类任务,例如 NER)
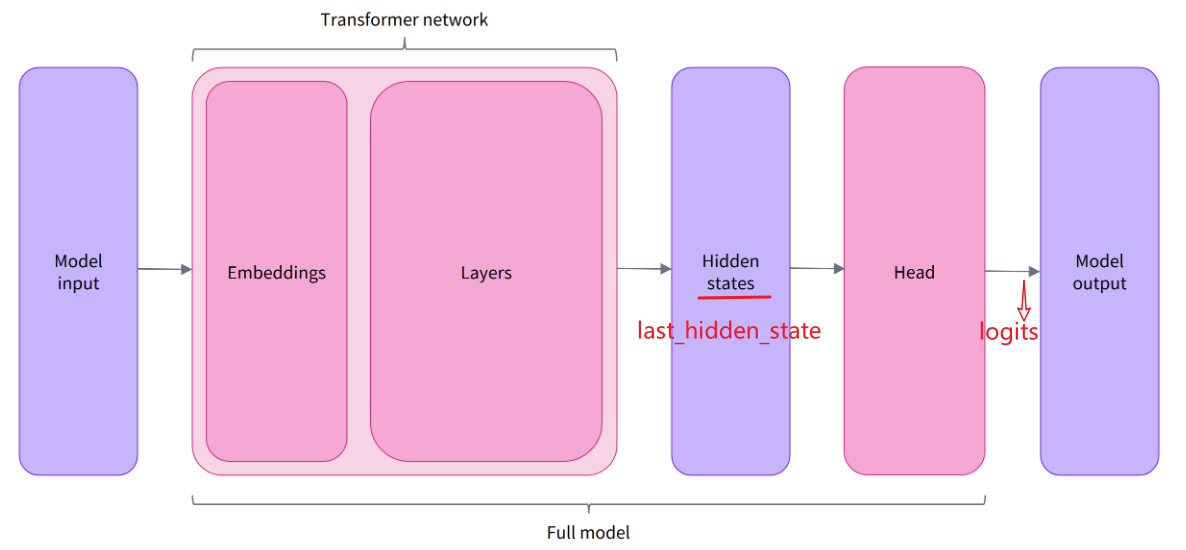
学习参考示例:(https://transformers.run/c2/2021-12-08-transformers-note-1/)
模型(Model)&分词器(Tokenizer)
模型(Model)
1 | from transformers import AutoModel |
HuggingFace 上的模型,通常只需要下载对应的 config.json 和 pytorch_model.bin,以及分词器对应的 tokenizer.json、tokenizer_config.json 和 vocab.txt。(具体模型可能存在一丢丢的不同)
- model.safetensors / pytorch_model.bin 等,模型文件
- config.json 模型配置文件
- vocab_size 字典数量(可识别文字符数)
- special_tokens_map.json 特殊字符
- tokenizer.json 字符及编码
- tokenizer_config.json 字典相关配置
- vocab.txt 字典(可识别字符)
分词器(Tokenizer)
- 按词切分(Word-based)
- 按字符切分(Character-based)
- 按子词切分(Subword)(“tokenization” 被切分为了 “token” 和 “ization”)
1 | '''分词器的加载与保存''' |
文本编码过程:1. 分词 2. 映射:将 tokens 转化为对应的 token IDs;
以 BERT 默认的子词分词策略为例:
1 | '''文本编码''' |
1 | ['using', 'a', 'transform', '##er', 'network', 'is', 'simple'] |
处理多段文本
示例:
1 | import torch |
1 | Input IDs: |
模型只接受批(batch)数据作为输入;由于通常 batch 中的文本有长有短,因此需要对其部分序列进行填充;
Padding 填充操作;Attention Mask 告诉模型哪部分内容是由自己填充的,从而不需要模型一同编码进去;
(若不设置 attention mask 模型会将其填充的部分作为原序列一起编码)不过实际应用中直接使用 tokenizer 分词器会自动构建 attention mask,截断等操作。
1 | # 前面的模型导入等操作同上~~ |
1 | tensor([[ 1.5694, -1.3895]], grad_fn=<AddmmBackward0>) |
由于 Transformer 模型对 token 序列的长度有限制,所以在处理长序列时需要其他的处理:设定最大长度截断输入序列;将长文切片为短文本块(chunk),对每个 chunk 编码;
padding="longest": 将序列填充到当前 batch 中最长序列的长度;padding="max_length":将所有序列填充到模型能够接受的最大长度,例如 BERT 模型就是 512;- 截断操作,
truncation参数控制,为True时大于模型最大接受长度的序列都会被截断;也可通过max_length参数控制截断长度; return_tensors参数设置指定返回张量格式;
1 | # 前面的模型导入等操作同上~~ |
1 | {'input_ids': tensor([ |
编码句子对
1 | from transformers import AutoTokenizer |
1 | {'input_ids': [101, 2023, 2003, 1996, 2034, 6251, 1012, 102, 2023, 2003, 1996, 2117, 2028, 1012, 102], |
添加 Token
add_tokens()添加普通 token:参数是新 token 列表,如果 token 不在词表中,就会被添加到词表的最后;(或设置额外参数添加特殊 tokenspecial_tokens=True)add_special_tokens()添加特殊 token:参数是包含特殊 token 的字典,键值只能从bos_token,eos_token,unk_token,sep_token,pad_token,cls_token,mask_token,additional_special_tokens中选择。同样地,如果 token 不在词表中,就会被添加到词表的最后。添加后,还可以通过特殊属性来访问这些 token,例如tokenizer.cls_token就指向 cls token;
1 | '''add_tokens()''' |
添加 token 后需要重置 embedding 矩阵的大小,将 token 映射到对应的 embedding 。通过 resize_token_embeddings() 函数实现;(新提那家 token 的 embedding 时随机初始化的)
1 | # 示例:添加两个特殊token |
根据新添加 token 的语义进行初始化。eg:将值初始化为 token 语义描述中所有 token 的平均值。
1 | # 分别为 [ENT_START] 和 [ENT_END] 编写对应的描述,然后再对它们的值进行初始化 |
1 | ['end', 'of', 'entity'] |
模型编码
模型是处理字符数据(编码与解码简单的理解)
1 | from transformers import BertTokenizer |






